次世代プログラミング言語Mojo
 Mojo、PythonとRu
Mojo、PythonとRuMojoは、Pythonの直感性、Rustのメモリ安全性、Zigのメタプログラミングを融合した新言語です。
AI開発に最適化され、GPUプログラミングも容易に行えます。
既存のPythonコードとの連携も可能で、パフォーマンスボトルネックの解消に貢献します。
現在開発が進められており、2026年にはコンパイラがオープンソース化される予定です。
Chris Lattner氏(LLVMやSwiftの開発者として知られる)が立ち上げた新言語「Mojo」が、その設計思想とパフォーマンスの高さから注目を集めています。2022年末にプロジェクトが開始され、現在Phase 1の開発段階とのことです。本記事では、Mojoの特長やロードマップ、そしてPythonとの連携について解説します。
複数の言語の良いところを組み合わせた設計
Mojoは、Pythonの直感的な構文、Rustのメモリ安全性、そしてZigの強力なメタプログラミングといった、既存のモダンな言語の良い点を組み合わせる形で設計されています。これにより、開発者は高い生産性を維持しつつ、安全で効率的なコードを書くことが可能になると説明しています。特に、コンパイル時に型チェックを行う静的型付け言語である点が、パフォーマンス向上に貢献していると考えられます。
AI開発に最適化されたパフォーマンス
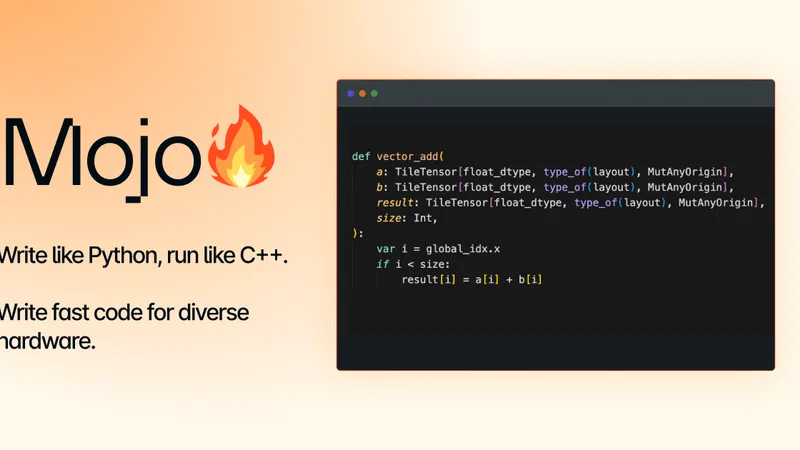
Mojoは、現代のAIシステムを動かす多様なハードウェア環境での最高のパフォーマンスを実現するように設計されています。GPUプログラミングも容易であり、ベンダー固有のライブラリや個別にコンパイルされたコードを必要とせず、CPUと同じ言語でGPUカーネルを記述できるとのことです。また、SIMD(Single Instruction, Multiple Data)を活用したベクトル化処理や、コンパイル時のメタプログラミングによるハードウェア最適化も容易に行えるため、AI開発におけるパフォーマンス向上が期待できます。
Pythonとのシームレスな連携
MojoはPythonとの相互運用性をネイティブにサポートしており、既存のPythonコードを書き換えることなく、パフォーマンスボトルネックを解消することが可能です。パフォーマンスが重要な部分だけをMojoで書き直し、段階的に移行していくことも容易だそうです。MojoコードはPythonに自然に取り込まれ、配布可能なパッケージとしてまとめることもできます。これにより、既存のPythonエコシステムとの親和性を保ちつつ、パフォーマンス向上を図ることが可能になります。
まとめ
Mojoは、まだ開発途上の言語ですが、その設計思想とパフォーマンスの高さから、AI開発をはじめとする幅広い分野での活用が期待されます。今後のロードマップに基づいた機能拡張や、Pythonとの連携の深化に注目が集まります。
原文の冒頭を表示(英語・3段落のみ)
For the complete Mojo documentation index, see llms.txt. Markdown versions of all pages are available by appending .md to any URL (e.g. /docs/manual/basics.md).Built differentModernMojo draws inspiration from the best parts of modern languages - like Python's intuitive syntax, Rust's memory safety, and Zig's powerful and intuitive compile-time metaprogramming.AI nativeMojo is built from the ground up to deliver the best performance on the diverse hardware that powers modern AI systems. As a compiled, statically-typed language, it's also ideal for agentic programming.Simply performantNo more choosing between productivity and performance - Mojo gives you both. You can start with simple and familiar programming patterns, and add complexity as you need it.GPU programmingMojo makes GPU programming accessible to everybody, without vendor-specific libraries and without separately-compiled code. You can finally write high-performance GPU kernels in the same language you use for CPUs.def vector_add( a: TileTensor[float_dtype, type_of(layout), element_size=1, ...], b: TileTensor[float_dtype, type_of(layout), element_size=1, ...], result: TileTensor[ mut=True, float_dtype, type_of(layout), element_size=1, ... ],): var i = global_idx.x if i < layout.size(): result[i] = a[i] + b[i]Python interopMojo natively interoperates with Python so you can eliminate performance bottlenecks in existing code without rewriting everything. You can start with one function, and scale up as needed to move performance-critical code into Mojo. Your Mojo code imports naturally into Python and packages together for distribution. Likewise, you can import libraries from the Python ecosystem into your Mojo code.# SIMD-vectorized kernel squaring array elements in place.def mojo_square_array(array_obj: PythonObject) raises: comptime simd_width = simd_width_of[DType.int64]() ptr = array_obj.ctypes.data.unsafe_get_as_pointer[DType.int64]() def pow[width: Int](i: Int) unified {mut ptr}: elem = ptr.load[width=width](i) ptr.store[width=width](i, elem * elem) vectorize[simd_width](len(array_obj), pow)Compile-time metaprogrammingMojo metaprogramming uses the same language as the run-time code, providing an intuitive system to maximize performance. You can build hardware-specific optimizations with conditional compilation, ensure memory safety with compile-time evaluation, eliminate costly runtime branches, and more—all with clearly defined intentions and zero-cost abstractions.# Generic struct equality using compile-time reflection.@always_inlinedef __eq__(self, other: Self) -> Bool: comptime r = reflect[Self]() comptime names = r.field_names() comptime types = r.field_types() comptime for i in range(names.size): comptime T = types[i] comptime assert conforms_to(T, Equatable), "All fields must be Equatable" if trait_downcast[Equatable]( r.field_ref[i](self) ) != trait_downcast[Equatable](r.field_ref[i](other)): return False return TrueRoadmapMojo was born in late 2022 and has come a long way, but there's still a lot to do.Phase 0Initial bring-upImplementing the core parser, defining memory types, functions, structs, initializers, argument conventions, and other language foundations.Phase 1in progressHigh performance CPU + GPU codingMaking Mojo a powerful and expressive language for writing high-performance kernels on CPUs, GPUs, and ASICs, while empowering developers to extend Python seamlessly.Phase 2Systems application programmingExpanding Mojo to support more application-level programming, with a guaranteed memory-safety model and more abstraction features that developers expect for systems programming.Phase 3Dynamic object-oriented programmingSupporting more of Python's dynamic features like classes, inheritance, and untyped variables to maximize compatibility with Python code.Open sourceThe Mojo standard library is fully open-source on GitHub and we welcome contributions! We also plan to open-source the Mojo compiler in 2026.We're committed to open-sourcing all of Mojo, but the language is still very young and we believe a tight-knit group of engineers with a common vision moves faster than a community-driven effort.If you'd like to get involved, join our developer community!Learn MojoJoin the community
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。