AIの記憶はまだ検索のように機能する
 精度の重要性
精度の重要性AIの記憶システムが抱える問題点を、PrecisionMemBenchが明らかにした。
多くのシステムが、記憶ではなく検索に基づいて構築されており、信頼性と透明性に欠けることが原因である。
精度の重要性は、ユーザーがAIシステムを信用して使用するかどうかを決定する要因であり、現在の記憶技術は不十分である。
AIの記憶機能が検索と同様の仕組みで構築されていることが問題視されている。この現象の背景と、今後の課題について解説する。
検索と記憶の違い
AIの記憶機能は検索と混同されがちだが、両者は本質的に異なる。検索は関連性の高い情報を返すが、記憶は状態を保持し、信頼性が求められる。特に、古い情報や不適切な情報が混入すると、信頼性が損なわれる。このため、記憶機能には高い精度が求められる。
精度の重要性
記憶の精度はユーザーの信頼を左右する。誤った情報が混入すると、ユーザーは信頼を失い、システムの利用をためらう。また、開発チームも情報の信頼性を確認する必要がある。このため、記憶機能には透明性と制御性が求められる。
課題と今後の方向
PrecisionMemBenchというテストでは、記憶システムの精度不足が明らかになった。特に、情報の信頼性を判断する仕組みが不十分なことが問題。今後は、記憶の信頼性を確保するための技術革新と、ユーザーへの透明性の向上が求められる。
まとめ
AIの記憶機能は検索と混同されがちだが、信頼性を確保するためには、精度と透明性が不可欠である。今後の課題は、記憶の信頼性を担保する仕組みの構築にある。
原文の冒頭を表示(英語・3段落のみ)
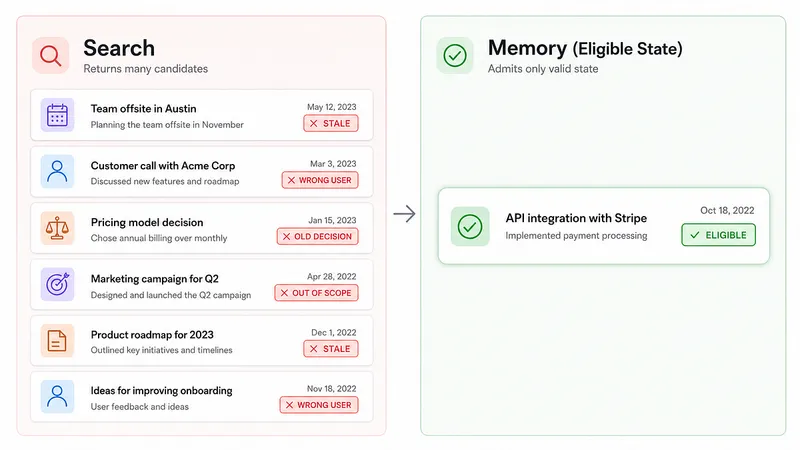
The field inherited retrieval because the infrastructure was already there. PrecisionMemBench made the cost of that assumption measurable.11 min readJust now--Press enter or click to view image in full sizeRetrieval can return many relevant-looking memories. Persistent memory requires a stricter boundary: only eligible state should reach the model.AI memory did not become search because anyone proved search was the right abstraction for persistent state.It became search because the infrastructure already existed.Embeddings existed. Vector databases existed. Hybrid search existed. Rerankers existed. RAG pipelines existed. The mental model was already sitting there: take past information, retrieve the most relevant pieces, put them into the context window, and let the model reason over them.That was practical. It was fast. It let teams build.Over time, the shortcut hardened into an assumption: if an AI system needs memory, memory should look like retrieval.PrecisionMemBench was designed to test the cost of that assumption.Not at the final-answer layer. Not by asking whether a model could recover from messy context. Not by giving credit when the right fact appeared somewhere in a pile of stale, conflicting, or scope-invalid facts.It tested the memory substrate directly.Given a current belief, stale alternatives, conflicting alternatives, unrelated facts, and scoped facts that should not apply, did the memory system retrieve only the belief that was eligible for the turn?That is the question persistent memory has to answer.Search can be fuzzy. Memory cannot.If I search the web and get a few irrelevant results, that is noise. If an AI assistant retrieves a stale preference, a superseded engineering decision, a fact from another user, or a memory from the wrong agent, that is not noise. It is state contamination.That is why precision matters.Precision is not an academic metric here. It is the difference between memory a user can trust and memory a user has to supervise.The adoption problem is trust, not desireThe reason this matters is not benchmark aesthetics.It is adoption.AI memory promises continuity, personalization, institutional knowledge, and agents that improve over time. Almost everyone understands why that would be useful. The problem is not that users dislike memory. The problem is that they do not trust unaccountable memory.Today, many systems ask users to accept an invisible process:The system remembered something.The retriever found something.The reranker ordered something.The model decided what mattered.The final answer sounded right.That is not enough.A user needs to know what was remembered, why it was remembered, whether it is still current, where it came from, and whether it was allowed to be used in this turn.A team needs even more. It needs scope boundaries. It needs auditability. It needs deprovisioning. It needs policy. It needs to know that one developer’s preference did not become a team rule, that one project’s decision did not leak into another repo, and that old state did not quietly override current state.Until those questions can be answered below the model layer, memory remains fragile.Useful in demos. Risky in production. Trusted only until the first stale or cross-scope fact leaks into an answer.If the field does not measure memory at the layer where memory actually fails, then we are choosing to normalize that state of affairs.That is not a path to mass adoption.Why the retrieval frame took holdThe retrieval frame took hold because it was convenient, not because it was inevitable.RAG gave the industry a working pattern: store text, embed text, retrieve similar text, put it in the prompt. That pattern works well enough for many knowledge tasks. If the goal is to answer a question from a document corpus, broad retrieval can be a feature. More context may help. A reranker can improve ordering. The model can synthesize.Persistent memory is different.Memory is not just information that might be relevant. Memory is accumulated state.State has rules.Who does this fact belong to?Is it still true?What superseded it?Was it asserted by the user, inferred by the model, or imported from a trusted source?Is it allowed in this workspace?Is it allowed for this user?Is it allowed in this mode?Should the model see it at all?Those are not ranking questions. They are eligibility questions.A retrieval system asks:Which candidates are most relevant?A memory system has to ask first:Which candidates are allowed to exist?That distinction is the center of the problem.Once an ineligible memory becomes a candidate, the memory layer has already failed. A reranker may push it down. A prompt may warn the model. The model may ignore it. But that is downstream recovery from upstream ambiguity.Recovery is not correctness.What PrecisionMemBench exposedPrecisionMemBench exposed a structural precision gap.It did not show that memory systems are useless. It showed that many systems are still built around a retrieval assumption that is poorly matched to persistent state.The clearest signal was not simply that scores were low. It was that the failure persisted across embedding scale.Across a roughly 20x model-size range, embedding systems clustered around the same precision ceiling. Larger embeddings did not close the gap. Better semantic similarity did not solve stale state, conflicting state, or scope invalidity.That matters because it separates a capability problem from an architecture problem.If the problem were mainly model capability, larger or better embeddings should move the ceiling substantially. If the problem is structural, then the system can get better at similarity without getting better at eligibility.That is what PrecisionMemBench showed.The memory systems could often find something related. The failure was deciding what should not be retrieved.And in memory, exclusion is not optional.The right fact surrounded by wrong facts is not a clean memory result. It is a contaminated one. A final answer may still come out right, but the substrate did not prove correctness. It handed the model a mess and relied on the model to recover.That is the difference between retrieval and memory.Retrieval can tolerate extra context.Memory has to preserve valid state.The response pattern is the evidenceThis piece does not speculate about intent.It treats public issues, pull requests, commits, discussions, and benchmark repositories as artifacts. The question is not why any team responded the way it did. The question is what the public record reveals about where memory correctness currently lives.The pattern is clear: when belief-level precision was pressured, retrieval-centric systems responded where their architecture gives them leverage.Filters.Rerankers.Eval additions.Wrapper changes.Metadata handling.Search configuration.Prompt and extraction adjustments.Those changes can be useful. Some are necessary. But they also show the constraint: once memory is built as retrieval, most available fixes happen downstream of the actual failure boundary.That is not a failure of execution. It is architectural lock-in.Mem0: the eval request reveals the real failure classThe Mem0 issue is important because it names the failure class directly.The request was not for another generic RAG benchmark. It asked for memory evaluation around stale information, conflicting memories, overwrite behavior, temporal relevance, and conflict resolution.Those are state-management problems.A search system can return multiple relevant documents and let the model synthesize. A memory system needs to know which belief is current, which belief was replaced, and which belief should be excluded.That distinction matters because Mem0 is not an obscure toy. It is one of the better-known memory systems in the space. When a production memory layer needs evaluation for staleness, overwrites, and conflicts, that is not a small edge case. It is the core problem showing through the retrieval abstraction.The point is not “Mem0 had an issue.”The point is that the issue itself describes memory as state while the dominant implementation pattern still treats memory as retrieval.That gap is the problem.AgentMemory: isolation is not rankingAgentMemory surfaced another class of failure: isolation.A pull request fixed a case where memory search needed to enforce AGENT_ID isolation. Before that fix, one agent could retrieve memory associated with another agent.This is exactly why memory cannot be treated as broad candidate retrieval plus ranking.A memory from the wrong agent should not be a lower-ranked candidate. It should be unreachable.That is the difference between relevance and eligibility.A reranker can order candidates. It cannot guarantee that invalid candidates never entered the set unless the system enforces that boundary before ranking.Isolation belongs before search results exist.If agent B can retrieve agent A’s memory, the problem is not that the wrong memory ranked too high. The problem is that the wrong memory was eligible at all.Hindsight: reranking cannot fix an upstream boundaryHindsight is useful because it is explicitly working in the memory/retrieval quality space. It is not ignoring the problem. It has memory infrastructure, a retrieval layer, and reranking aimed at improving result quality.That makes the result more important, not less.A cross-encoder reranker can improve ordering. It can help decide which retrieved candidates look more relevant. But it does not change the primary failure boundary if ineligible memories have already entered the candidate set.This is the limit of treating precision as a reranking problem.If the first-stage retrieval admits stale, conflicting, or scope-invalid state, then the system is relying on a later layer to clean up a mess the memory substrate created. Sometimes that will work. Sometimes it will not. But it is not the same as proving that only eligible state reached the model.That is why answer-level evaluation can hide the failure.The model may still produce a good answer. The judge may mark it correct. The system may look fine at the surface.But the memory layer did not demonstrate precision. It demonstrated recovery.gbrain: the exception that proves the pointThe most constructive public response came from gbrain.Their eval repository did not simply reject the benchmark, hide the weak number, or patch around one case. It treated PrecisionMemBench as a measurement primitive and then extended the frame.That matters.PrecisionMemBench was intentionally narrow. It tested belief-level retrieval precision under stale, conflicting, and scoped memory conditions. It did not claim to measure every memory failure. It did not cover every agent behavior. It isolated one failure class sharply.gbrain’s BrainBench work is interesting because it added adjacent failure categories instead of pretending the original category did not matter. It introduced memory conformance metrics around know-to-ask failure, push recall, precision, write-back fidelity, continuity, and isolation.That is what engaging with the actual problem looks like.Not every benchmark has to measure everything. A good benchmark should make one hidden failure visible enough that other teams can build the next measurement layer around it.That is the productive path.PrecisionMemBench exposed substrate precision. BrainBench extended the memory conformance surface. That is how the field should move: not by collapsing every failure into final-answer quality, but by separating the layers where memory can fail.The pattern is architectural lock-inThe public record shows serious teams responding in serious ways.That is exactly why the pattern matters.These are not random demos. These are teams building real memory infrastructure. And when pressured on belief-level precision, the visible fixes clustered around the same kinds of changes: add filters, improve retrieval, patch isolation, tune ranking, modify wrappers, add evals, pass more metadata, or ask the model to reason better.Again, some of that work is valuable.But it does not necessarily move correctness to the right layer.A system can add temporal metadata and still rely on retrieval to surface stale facts.A system can add a reranker and still admit invalid candidates.A system can improve extraction and still confuse current state with old state.A system can add graph structure and still rely on traversal/ranking to infer eligibility.A system can publish internal benchmark runs and still not answer how comparable external boundaries should work.This is what architectural lock-in looks like.When your system is built around retrieval, the available repairs tend to be retrieval-shaped.That is not a moral failure. It is a design constraint.But new builders should pay attention to it.What this means if you are building nowIf you are building an agent memory system today, the field’s consensus can look stronger than it is.Most systems use retrieval not because retrieval was proven to be the right model for memory, but because retrieval was the available toolchain.That matters.If you start from the same place, you inherit the same ceiling: broad candidate generation, downstream ranking, prompt-time reconciliation, and model-dependent recovery.You may improve the details. You may use better embeddings. You may use a graph. You may add a reranker. You may attach timestamps. You may ask the LLM to resolve conflicts. You may pass more metadata.But unless eligibility is enforced before candidate generation reaches the model path, you are still asking downstream intelligence to compensate for upstream ambiguity.That is the decision new builders still get to make.Existing teams have sunk cost. They have users. They have APIs. They have integrations. They have mental models. They cannot simply rip out their retrieval layer because a benchmark exposed a structural gap.New builders can.They do not have to inherit retrieval as the default abstraction for memory.They can start with state.They can ask:What is the unit of memory?What makes a belief current?What supersedes it?What scope owns it?What provenance is required?What control mode allows it?What makes it ineligible?What proof exists that the wrong state was excluded?Those are the questions memory infrastructure should start with.Search can come later.The cost of conflating memory and searchThe field conflated memory and search for practical reasons.That does not make the conflation harmless.The cost is now measurable.It shows up when embedding scale does not close the precision gap.It shows up when stale facts remain retrievable.It shows up when conflict resolution is treated as an eval category instead of a state invariant.It shows up when cross-agent isolation has to be patched at search time.It shows up when rerankers are asked to rescue precision after invalid candidates have already entered the set.It shows up when teams dispute wrappers because the evaluation boundary determines what logic gets to participate.This is not just a benchmark argument.It is the reason AI memory is not yet trusted as infrastructure.Users do not want memory that silently accumulates context and asks the model to sort it out. Teams do not want memory that might mix scopes, preserve stale decisions, or inject uninspectable state into production workflows.They want continuity, but they also want control.They want personalization, but they also want proof.They want institutional memory, but they also want boundaries.That is the gap between AI memory as a feature and AI memory as infrastructure.The real takeawayPrecisionMemBench did not show that memory systems are useless.It showed that many of them are still built in the wrong frame.They are thinking like search.Search tries to find enough relevant information for a model to reason over.Memory has to maintain eligible state over time.That difference sounds subtle until the first stale preference, old decision, wrong user fact, or cross-agent memory leaks into a production turn.Then it becomes obvious.The future of AI memory will not be won by the system that retrieves the most context. It will be won by the system that can prove what it remembered, why it remembered it, whether it is still current, and why everything else was excluded.The people who can act on this fastest are not necessarily the teams with the most retrieval infrastructure.They are the builders who see the assumption early enough to choose differently.Memory and search are different problems.The field treated them as the same because it was practical.Now we can measure the cost.The next step is deciding whether to keep patching around that cost, or build memory from the beginning as state.
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。