臨床AIツール、医療ベンチマークで大型言語モデルに敗れる
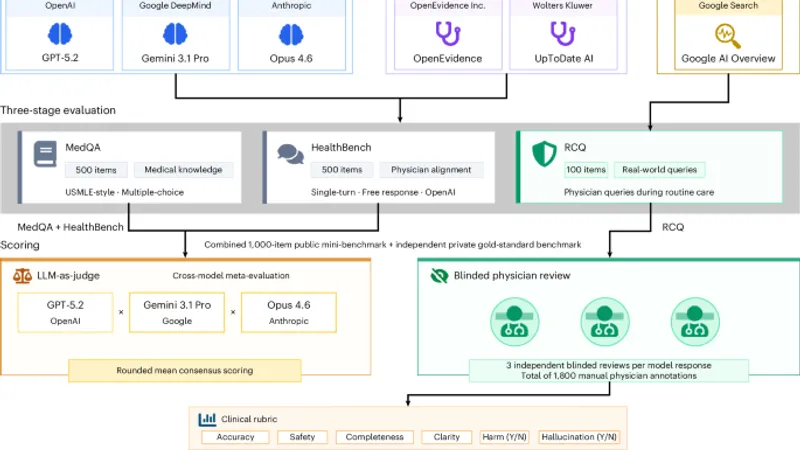 一般化大型言語モデルが臨床A
一般化大型言語モデルが臨床A大型言語モデルと臨床AIツールの性能を比較した研究によると、一般化大型言語モデルが医療ベンチマークで臨床AIツールを上回った。
臨床AIツールは、自動化されたGoogle検索AIオーバービューと同等の性能であった。
医療分野でのAI活用が進む中、一般向け大規模言語モデルが専門分野向けのAIツールを上回ることが明らかになりました。この研究は、医療分野での実際の評価が不足している専門AIツールと、最新の一般向けLLMを比較し、その性能を検証しました。
医療AIツールと一般LLMの比較
研究では、OpenEvidenceとUpToDate Expert AIという医療専門AIツールを、GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6などの最新の一般向け大規模言語モデルと比較しました。この比較は、医療知識の評価、臨床現場での実際の使用、医師の評価の3段階で行われました。
実際の臨床環境での評価
医師が実際に使用するリアルなクエリを基にした評価が行われました。12人の米国医師が、モデルの出力を盲検して評価し、1,800のモデルとクエリの注釈を作成しました。この評価では、最新のLLMが医療専門AIツールを上回ることが確認されました。
今後の課題と展望
研究結果は、医療AIツールが臨床現場に導入される前に、独立した実世界での評価が求められることを示しています。今後は、AIツールの信頼性や安全性を確保するためのさらなる検証が不可欠です。
まとめ
この研究は、医療分野でのAI活用において、一般向け大規模言語モデルが専門分野向けツールを上回る可能性を示しました。今後は、AIツールの信頼性と安全性を確保するための実世界での評価が重要です。
原文の冒頭を表示(英語・3段落のみ)
Brief Communication
Open access
Published: 12 June 2026
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。