LLMを判定者として使用するメリット
 多次元の品質と一貫性を判断
多次元の品質と一貫性を判断LLM-as-a-Judgeは、生成器の出力を受け取り、qualityやgapを認識し、特定のガードレールやルーブリックに照らして評価する。
多くのアプリケーションシナリオで有効で、品質管理、ベスト-OF-N選択、自己改善ループ、エージェントステップ検証などを実現する。
LLM-as-a-Judge(大規模言語モデルとしてのジャッジ)という概念についての解説記事。この技術は、生成モデルとジャッジモデルを分離して、品質管理や複数の評価基準を効率的に実行する仕組みを提供します。
生成とジャッジの役割分離
生成モデルは文脈に基づいて出力を生成しますが、ジャッジモデルはその出力を評価します。生成モデルは一連のタスクをバランスよく処理する必要があるのに対し、ジャッジモデルは特定の基準に応じて出力をチェックできます。
ジャッジの多様な用途
ジャッジモデルは品質管理や候補選択、自己改善ループなど、オンラインとオフラインのさまざまな場面で活用されます。また、トレーニングデータのフィルタリングや合成アノテーションにも利用されます。
多モーダル理解におけるジャッジの特徴
多モーダル理解では、ジャッジはテキスト応答をマルチモーダル入力に基づいて評価します。これにより、ジャッジが本当にマルチモーダルである必要があるか、あるいは単にテキストベースの評価を行うかが重要になります。
まとめ
LLM-as-a-Judgeは、生成モデルとジャッジモデルの役割分離によって、品質管理や複数の評価基準を効率的に実行する仕組みを提供します。今後の研究では、より高度な評価基準や多モーダル理解の改善が求められます。
原文の冒頭を表示(英語・3段落のみ)
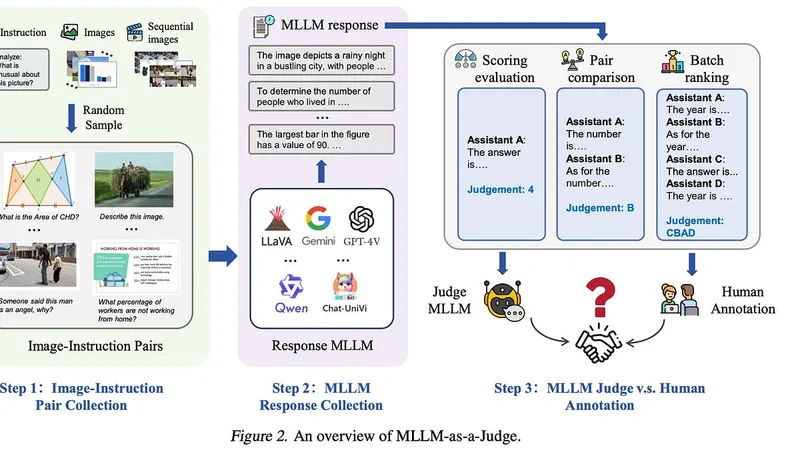
This writeup is an introduction on (Multimodal) LLM-as-a-Judge - a wide overview rather than a deep technical discussion.Let’s begin by addressing this common question: if we provide the same context to both the generator and judge, why would a (Multimodal) LLM-as-a-Judge add value? Below are some common reasons:Verification is often easier than generation - a common metaphor here is “more people can critique and appreciate great artwork than create it.” The judge does not need to generate high quality and comprehensive answers - it just needs to recognize quality or gaps in one.“Providing the same context” is not exactly true. The judge receives the generator’s output - e.g., retrieved frames, reasoning path, and final conclusions - in addition to the original context. Furthermore, compared to the original context, the additional artifact - the generator’s output - tends to be more specific to the actual problem to solve. The judge can compare it against specific guardrails and rubrics, and check consistency and gaps.You can have multiple judges, one for each specific dimension, thereby breaking down complex matrices of quality and consistency requirements into more tractable metrics. In contrast, generators need to balance all these requirements in their output.The generator often commits sequentially - token by token, chunk by chunk. The judge, in contrast, can review the final output holistically and catch errors or inconsistencies at a higher level.Next, let’s demystify a common misconception: that a judge is only useful for evaluation. In practice, LLM-as-a-Judge has many application scenarios across both online / inference and offline / training:Online / Inference timeQuality Control: the judge can reject outputs that fail predefined quality rubrics, or escalate them to a human-in-the-loop - e.g., rejecting a multimodal agent’s answer if it isn’t grounded in the retrieved frames.Best-of-N selection: the judge can pick the best from multiple candidates (or reasoning trajectories) the generator outputs - e.g., sampling five reasoning paths through a video and selecting the one with the highest grounding and consistency scores.Self-refinement loops: the judge critiques the generator’s first-pass output (”reasoning skipped frames 30–45”) and the same generator revises with the judge’s feedback, iterating until the output clears the predefined quality bar.Input into a downstream editor / post-processor: similar to self-refinement, except the judge’s feedback - e.g., missing visual elements, weak grounding, hallucinated entities - goes to a separate editor / post-processor, which fixes the issues directly rather than regenerating from scratch.Agentic step verification: beyond judging the final output, the judge can validate each intermediate action - tool call, retrieved frame, reasoning step - before the agent commits to the next one, catching errors mid-trajectory rather than after the full answer is produced.Offline / Training timeTraining data filter: the judge can help filter existing human or synthetic data - e.g., removing flawed, ungrounded, or unverifiable reasoning trajectories - to curate higher quality training datasets.Synthetic annotator: the judge can help annotate final outputs, trajectories, or intermediate steps - e.g., labeling (query, agent trajectory, final output) triples - to scale training data for the generator beyond what human annotators can produce.Reward function for reinforcement learning: the judge can provide scalar rewards or preference pairs (chosen vs. rejected) for various RL methods, scaling beyond what human preference labeling can support.LLM-as-a-Judge can be applied across a diverse set of problems - for this writeup, I want to specifically discuss Multimodal LLM-as-a-Judge for multimodal understanding.MLLM-as-a-Judge (Chen et al. 2024) - the first comprehensive study of Multimodal LLM-as-a-Judge - built human-annotated benchmarks for image-instruction pairs spanning image captioning, math reasoning, text reading, and infographics understanding. It assessed MLLM judgment's alignment with human annotators across three settings: scoring evaluation, pairwise comparison, and batch ranking. It showed that while MLLMs are closer to human judgment on pairwise comparison, there are still significant gaps in scoring and batch ranking. Furthermore, MLLM-as-a-Judge exhibits various biases (position bias, length bias, and self-preference), hallucinations, and inconsistencies.JudgeAnything (Pu et al. 2025)'s TaskAnything benchmark spans 15 any-to-any modality categories - for both generation and understanding - and its JudgeAnything evaluates judging over those tasks. The paper showed that while MLLM-as-a-Judge is promising for understanding (best performance is still with pairwise comparison), there are still significant challenges for generation. It also outlined three different judgment settings (how judges are elicited):Overall: direct judging, where the judge directly provides reasoning and a final judgmentRubric: the judge is required to judge based on fine-grained rubrics before making a final judgmentChecklist: the judge first evaluates against detailed checklists - curated through a human-in-the-loop process - before making a final judgmentAcross these settings, the paper showed that MLLM-as-a-Judge can be enhanced by well-constructed rubrics and checklists.A key characteristic of judging in multimodal understanding is that the judge is typically evaluating a text response conditioned on multimodal input. This has major implications - either the judge needs to be truly multimodal and rely on its own perception capabilities, or the judge is just grading text against a (possibly flawed) video description or audio transcription, i.e., a purely text-based LLM-as-a-Judge setup. The above two studies focused on the former, whereas the study below compared the two options.VideoJudge (Waheed et al. 2025) introduced 3B/7B MLLM judges specialized to evaluate text responses conditioned on videos, with two notable findings:Small specialized judges can match or surpass much larger general-purpose judges; furthermore, VideoJudge generates test-time rubrics for fine-grained, interpretable scoring.Genuinely multimodal judges can outperform text-only LLMs that only see the text description, and long chain-of-thought reasoning is not a viable mitigation for the video perception gap.The process to bootstrap MLLM-as-a-Judge training data in VideoJudge works as follows:Start with seed data - human-provided gold responses - from three large-scale video instruction–response datasets (VideoInstruct-100K, VCG-Plus-112K, VideoChat2-IT); for multi-turn dialogues, only the first human–assistant exchange is used.A (data) generator model produces (N−1) candidate responses, where N is the rating scale.A (data) evaluator model rates each candidate response and provides the corresponding reasoning.Compute the deviation between the generator’s rating and the evaluator’s assigned rating - for candidates with a large deviation, the generator is prompted again with the evaluator’s feedback to improve its response.(Multimodal) LLM judges are not ground truth - they are also models requiring evaluation, calibration and quality control.Evaluation of MLLM-as-a-Judge is anchored on agreement with human judgment, as scaling human annotation is the biggest motivation. As showcased in the studies reviewed above, standard practices are:Curate a human/expert-annotated golden dataset.Not all human datasets are golden - it is critical to make sure humans agree on these annotations first. In addition, it is important to distinguish "low agreement from poor guidelines" (something we should fix) from "low agreement from intrinsic subjectivity" (a hard task-specific ceiling that indicates the task is worth breaking down further).Measure agreement with human judgments. Similar to the point above, if the agreement rate is low - especially for clear-cut cases - the MLLM-as-a-Judge needs further iteration.Evaluate the reasoning as well - rubric-level evaluation is crucial especially for production scenarios where the rationales for the final output also matter, not just the output itself.Calibration and quality control of MLLM-as-a-Judge:Confidence-based escalation: estimate the confidence of the judge and escalate to human evaluation when low, in order to guarantee a certain level of human agreement. Similarly, to further optimize scalability, smaller, faster judges can be deployed at scale and escalate to stronger, more time-consuming ones only when confidence is low.Juries instead of judges: mix judges across different model families and use disagreement among them as a signal to flag low confidence / high ambiguity for human review. However, a jury of judges that have the same limitations (e.g., poor perception capabilities) will agree confidently and wrongly - instead of expanding the jury, we should prioritize fixing these limitations or relying on human-in-the-loop escalations.Debiasing: randomize candidate ordering to counter position bias; intentionally control for length bias; systematically audit for self-preference.It is critical to point out that optimizing generators against under-evaluated or under-calibrated judges is extremely harmful: going back to the multifaceted value of MLLM judges, using a poor judge for RL or training curation will greatly increase the risk of reward hacking or persistent model blind spots. For all these reasons, calibration and bias auditing must become prerequisites, not afterthoughts.Reliability is task-dependent: There is no such thing yet as a “universally reliable” Multimodal LLM-as-a-Judge. Evaluation is intrinsically application-dependent - a feature, not a bug. Reliability of the judge for one task is never guaranteed to transfer to another.Long-form video remains hard: VideoJudge showed that baseline MLLM judges drop substantially on LongVideoBench, even as their trained judges held up - underscoring that long-video judging remains hard without specialized adaptation.Perceptual bias persists: A recent work, Perceptual Judgment Bias (Park et al. 2026), showed that MLLM judges tend to “reward plausible narratives over perceptually correct answers”, biasing toward text over visual evidence. This paper proposed a new dataset and a training framework to improve perceptual fidelity, pointing to opportunities for strengthening MLLM judges.Taken together, these findings show that the asymmetry between generation and verification articulated earlier is likely larger for some tasks (factual consistency, rubric-checking) than others (long-context temporal grounding, fine-grained perception).
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。