コードで学ぶステート空間モデル(SSM)の仕組み
 SSMとAttentionの
SSMとAttentionの従来のTransformerモデルは、アテンション機構により過去全てのトークンを参照するため、計算量が$O(N^2)$となり、メモリ負荷が高いという課題があります。
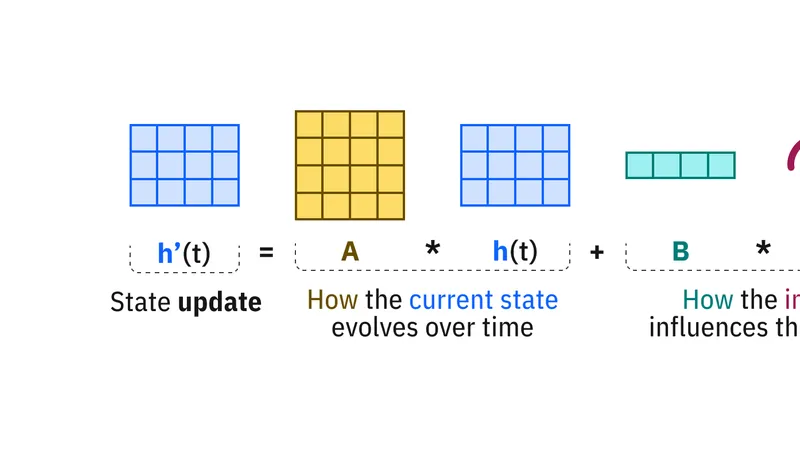
一方、SSMは過去の情報を固定サイズの隠れ状態に圧縮することで、トークンごとの計算量を$O(1)$に抑え、効率性を実現しています。
しかし、純粋なSSMは「線形時不変(LTI)」な性質を持つため、全てのトークンに対して同じ再帰則が適用されてしまいます。
この固定的な重み付け(畳み込みと類似)は高速化に貢献する一方、内容に応じて情報を選択的に処理する「ゲーティング」を行うことができないというトレードオフがあります。
原文の冒頭を表示(英語・3段落のみ)
- Karthik Ragunath Ananda Kumar
I built a minimal state space model in pure PyTorch and trained it character-by-character on tiny-shakespeare dataset to understand how SSMs and Mamba actually work. This post walks through that code and explains what each piece does, why it’s there, and how it all fits together.
A language model takes a sequence of tokens and predicts the next one. Transformers do this with attention: every new token looks at every previous token via $\text{softmax}(QK^T)V$, which costs $O(N^2)$ for training and forces you to keep every previous K and V in memory during inference.
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。