AIの記憶問題を解決する12のシステム
 stateless AIの限
stateless AIの限stateless AIは会話ごとに情報を忘れるため、長期的なユーザー記憶や個人化が困難。
多くのチームは独自のアプローチでこの問題に対処している。
12のシステムを比較し、特徴や使用例を紹介する。
AIチャットボットがユーザーの過去の会話履歴を忘れてしまう問題について、技術的な解決策が紹介されています。この記事では、10の主要なシステムがどのように機能し、それぞれの特徴や適した用途を解説します。
AIの記憶の限界
AIチャットボットは、ユーザーの過去の会話履歴を忘れてしまうという問題があります。これは、モデルが一度の会話ごとにゼロから始める必要があるためです。この状態は「ステートレスAI」と呼ばれ、ユーザーが長期間の会話や個人化されたサービスを求める場合に大きな障害となります。
記憶の種類と課題
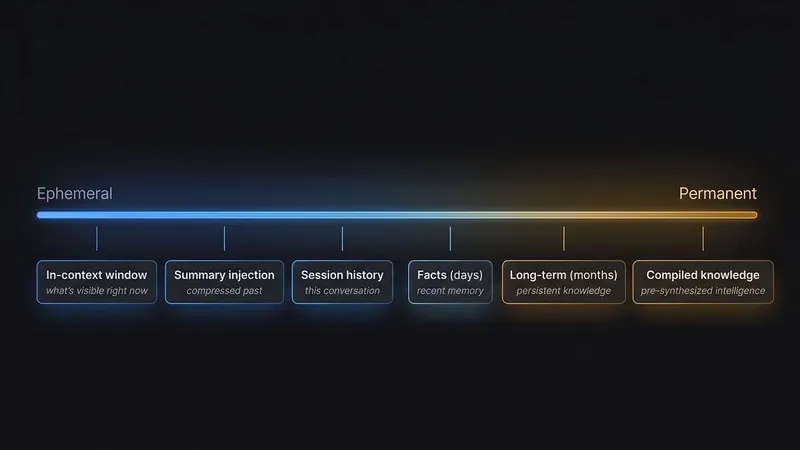
AIの記憶には、一時的なものから永久的なものまで幅広い種類があります。個人化や機関知識という2つの根本的な課題があります。多くのシステムはどちらか一方を解決していますが、両方を同時に扱えるものは限られています。
技術的な基盤とシステムの特徴
これらのシステムは、ベクターエンコーディングやRAG(リトリーバル拡張生成)などの技術を基盤としています。mem0やLettaなどの代表的なシステムは、それぞれ異なるアプローチを取っており、ユーザーのニーズに応じて選ぶ必要があります。
まとめ
AIチャットボットの記憶問題を解決するための10のシステムが紹介されました。それぞれの特徴や用途を理解し、ユーザーのニーズに合った選択が重要です。
原文の冒頭を表示(英語・3段落のみ)
14 min readJust now--Every time you start a new conversation with an LLM, you start from zero.The model has no idea who you are. It doesn’t know what you’ve built, what you care about, or what you’ve already tried. You can spend months talking to it, and every Monday morning, you have to reintroduce yourself from scratch.This is the stateless AI problem. And it’s not a limitation of the model’s intelligence. It’s a limitation of how conversations are structured. The model only sees what’s in its context window: the text in front of it right now. Nothing before. Nothing after.For one-shot tasks, statelessness is fine. But for anything requiring real personalization, like building a product that knows its users, a coding assistant that remembers your codebase, or a mentor that tracks your progress, statelessness is a product killer.The field has responded with over a dozen distinct approaches to solving this. Most teams pick one and hope for the best. This article maps all of them: what each system actually does, when it wins, when it loses, and which one you should be building with right now.The Mental Model Before the SystemsBefore comparing frameworks, you need to understand the spectrum. Memory for AI systems ranges from ephemeral to permanent:Press enter or click to view image in full sizeEvery memory system is making a bet about where on this spectrum to focus. Some systems are optimized for retrieving facts from long conversations. Others are designed to compile knowledge over weeks. Others focus on tracking how facts change over time. The choice of system is really a choice about what kind of memory problem you have.There are also two fundamentally different problems hidden under the label “AI memory”:Personalization: remembering who the user is, what they prefer, what they’ve told youInstitutional knowledge: accumulating domain expertise, operational patterns, learned workflowsMost systems solve one of these well. Few solve both.The Primitives: What All Systems Are Built FromBefore the frameworks, the vocabulary.Vector embeddings convert text into lists of numbers that encode meaning. Semantically similar text produces geometrically similar vectors, so you can search by meaning rather than keywords. The key metric: use cosine similarity (measures angle between vectors), not L2/Euclidean distance (measures magnitude). Switching from L2 to cosine is the most impactful single fix for most broken retrieval systems. Takes 15 minutes.BM25 is keyword search that still works. It scores documents by term frequency × inverse document frequency, great for exact matches like usernames, IDs, or specific technical terms that semantic search misses. Hybrid retrieval combines both signals, and it’s not optional for production systems:final_score = α × cosine_similarity + β × bm25_normalizedRAG (Retrieval-Augmented Generation) is the standard pattern: embed a query → find relevant chunks → inject them into the LLM prompt → generate a grounded response. Its quality ceiling is retrieval quality. Garbage retrieval, garbage response.Chunking is why you can’t just embed a 100-page document. Too small (50 chars) loses context. Too large (5000 chars) dilutes the embedding. For atomic facts: 150–400 chars. For procedural workflows: 2000–4000 chars.With those in hand, here are the 10 systems that actually matter.The 10 Systems1. mem0: The Fastest Path to ProductionGitHub: ~48,000 stars | License: Apache 2.0 | Funding: $24M raised Oct 2025mem0 is the most widely deployed semantic memory layer as of mid-2026. Its core value proposition: pip install mem0ai, five lines of code, and you have working memory.The architecture runs LLM-based fact extraction on every conversation turn, stores extracted facts in a vector database (Qdrant, FAISS, Pinecone, or ChromaDB), and retrieves with a 4-signal hybrid stack: semantic similarity + BM25 keyword matching + entity linking boost + temporal recency.The April 2026 redesign removed the DELETE operation. When a user says “I moved from Mexico City to Dubai” and the system already knows “User lives in Mexico City,” both facts are stored. Conflicts are resolved at read-time via temporal recency, with the newer fact surfacing higher. This ADD-only approach cut extraction cost by 60–70% (one LLM call instead of three) and eliminated permanent data loss from wrong DELETE decisions.What it’s great at: Any SaaS product where multiple users need personalized memory. user_id isolation is built in. The free tier handles 10K memories. If you need memory and you need it now, this is the answer.What it misses: Graph features require $249/month Pro. The flat vector store means “I like pizza” and “I love pizza” are stored as separate facts. No temporal validity on facts, so you know the newer fact ranks higher, but the old one never truly expires. And if your memory problem is graph-shaped (entities, relationships, how they change over time), mem0 is the wrong layer.2. Letta (formerly MemGPT): The Self-Editing AgentGitHub: ~21,000 stars | License: Apache 2.0 | Funding: $10M seedLetta’s insight is drawn from operating systems. Your computer creates the illusion that programs have unlimited RAM by transparently paging data to disk and retrieving it when needed. Letta does the same for LLMs, managing what stays in context (“fast memory”) and what goes to external storage (“disk”).The architecture has three tiers:Core Memory: a compact block always present in the system prompt. Contains identity facts, preferences, current context. The agent can directly rewrite this in real time via tool calls:core_memory_replace( label="human", old_text="User lives in Mexico City", new_text="User moved to Dubai, June 2026")The moment the user corrects something, it’s updated. No lag. No batch job. This is what separates Letta from everything else: the agent actively manages its own understanding.Recall Memory: the conversation history. Searchable. When the context window fills, oldest messages are compressed via auto-summarization, keeping conversations effectively indefinite.Archival Memory: unlimited vector storage (SQLite for dev, Postgres + pgvector for production). The agent calls archival_memory_insert() to save things worth keeping long-term, and archival_memory_search() to retrieve them.What it’s great at: Stateful agents where the core value is that the AI genuinely updates its understanding as it learns new things. The real-time self-edit is the gold standard for conversational memory.What it misses: It’s a framework, not a library. You adopt Letta’s architecture, not just a memory module. A hallucinating agent can corrupt its own memory. Quality of self-editing depends entirely on LLM quality. No built-in contradiction detection.3. Graphiti / Zep: Temporal Knowledge GraphsGitHub: ~24,000 stars (Graphiti) | License: Apache 2.0 | Paper: arXiv 2501.13956Graphiti is Zep’s open-source temporal knowledge graph engine (Zep Community Edition was deprecated in 2025; use Graphiti directly). It’s the right answer to a question that most systems get wrong: facts change over time, and you need to know when a fact was true, not just whether it is.The key innovation: every fact in the graph has explicit validity timestamps.Entity: Alan lives_in → Mexico City | valid: 2025-01-01 → 2026-06-01 lives_in → Dubai | valid: 2026-06-01 → presentWhen you query “where does Alan live?” You get Dubai. The old fact isn’t deleted, it’s expired. Query “where did Alan live in early 2025?” You get Mexico City, correctly. This is temporal validity as a first-class feature, not a retrieval score.The architecture layers three retrieval mechanisms: semantic embeddings for similarity, BM25 for keyword matching, and graph traversal for relational queries. Combined, this hits sub-200ms retrieval latency. Benchmarks: 94.8% on DMR, up to 18.5% accuracy improvement over RAG baselines on LongMemEval enterprise tasks.What it’s great at: Any system where facts evolve over time, and where relationships between entities matter: a mentor tracking a founder’s evolving relationships, a CRM-style AI that needs to know how a customer’s situation changed, or any long-lived agentic system.What it misses: More complex to set up than mem0. Entity resolution is an open problem (“Alan the founder” and “Alan the writer” are different; the system needs to figure that out). The free tier caps at 1K credits.4. Cognee: Graph-First MemoryGitHub: ~12,000 stars | License: Apache 2.0 | Funding: €7.5MCognee takes a different bet: rather than retrieving the most similar text chunks, it builds a queryable knowledge graph over everything you’ve ingested, and uses vector search as a hint for graph traversal rather than as the retrieval mechanism itself.The architecture runs three linked storage systems simultaneously:Graph store (entities, relationships): Kuzu by default, Neo4j/Memgraph/FalkorDB supportedVector store (semantic embeddings): LanceDB by default, Qdrant/pgvector supportedRelational store (chunks, provenance): SQLite by default, PostgreSQL supportedThe cognify pipeline runs six stages on every document: classify → verify → chunk → LLM entity/relationship extraction → summarize → embed. The result: every graph node has a corresponding embedding, so you can move between semantic similarity and relational traversal without losing coherence.The default retrieval mode is GRAPH_COMPLETION: vector search finds candidate entities, then the graph is traversed to build structured multi-hop context before generation. Complex queries like "how has Company X's relationship with their market position changed over the past year?" become tractable.Cognee runs fully locally (no external DB required by default). It ingests from 30+ data sources including text, images, and audio.What it’s great at: Institutional knowledge problems: document corpora, codebases, competitive intelligence, domain expertise accumulation. If your memory problem is shaped like a graph, this is built for it.What it misses: Python-only (no TypeScript SDK as of mid-2026). Smaller community than mem0 or Letta. Slower on pure personalization (user facts, conversational memory), and it’s optimized for structured knowledge, not conversational episodics.5. Hindsight: The New Benchmark LeaderGitHub: ~4,000 stars (growing fast) | Pricing: Free self-hostedHindsight is the newest system on this list and the one with the highest verified benchmark: 94.6% on LongMemEval as of mid-2026. It does something others don’t: it runs four retrieval strategies in parallel, then reranks with a cross-encoder.Incoming query ↓ simultaneously: ├── Semantic search (vector similarity) ├── Keyword search (BM25) ├── Graph traversal (entity connections) └── Temporal search (recency + validity) ↓Cross-encoder reranking across all results ↓`reflect`: LLM synthesis across top results into coherent context ↓Response generationThe reflect feature is the key differentiator: instead of injecting raw retrieved chunks into the prompt, Hindsight synthesizes them first. The LLM sees a coherent, deduplicated summary of what's known, not a pile of potentially contradictory fragments.The cost: reflect adds 100–600ms latency versus 10–50ms for vector-only systems. Whether that matters depends on your use case.Hindsight is also MCP-first, designed to plug into Claude’s Model Context Protocol natively, which makes it a strong fit for anyone building on top of Anthropic’s tooling.What it’s great at: High-accuracy retrieval where latency tolerance exists. Anyone building with Claude/MCP who wants the best benchmark numbers without a heavy framework commitment.What it misses: Newest project with a smaller ecosystem and fewer documented production deployments. reflect latency is real.6. HippoRAG: Associative MemoryPaper: arXiv 2405.14831 (v1), 2501.14247 (v2) | Lab: StanfordHippoRAG is the most biologically-grounded system in this list. The hippocampus is your brain’s indexer for episodic memory; it doesn’t store memories, it builds an associative index that lets you traverse from one memory to adjacent ones. Seeing an old classroom triggers a teacher’s face, which triggers a lesson, which triggers a conversation with your dad about it. None of those connections were explicitly stored. They emerged from associative indexing.HippoRAG applies this to RAG. At indexing time, an LLM extracts entities and relationships, building a knowledge graph. At retrieval time, instead of returning top-K semantically similar chunks, it runs Personalized PageRank (PPR) from the query entities through the graph, propagating relevance associatively across connected nodes, with no additional LLM calls at retrieval time.The result: query “pricing” and you get not just memories that mention pricing, but memories about customer discovery, revenue model, and the specific conversation where pricing anxiety first appeared, all of them associatively connected.Benchmarks: +20–30% over standard RAG on PopQA multi-hop questions. Consistently dominates on queries requiring more than 4 reasoning hops.Key advantage over GraphRAG: Incremental indexing. Add a new memory → extract entities → add to graph → done. No $2–7/document re-indexing. Scales naturally for personal memory use cases.7. A-MEM: Zettelkasten for AIPaper: arXiv 2502.12110 (Rutgers, Feb 2025) | Code: github.com/agentic-memory/amemA-MEM applies the Zettelkasten note-taking philosophy to AI memory. Every existing system appends new memories to a store and retrieves the most similar ones later. The store is flat and static; memories don’t affect each other after insertion. A-MEM breaks this pattern.When a new memory arrives, A-MEM doesn’t just store it. It:Finds semantically related existing memoriesCreates explicit links between the new memory and those neighborsContextually refines the linked existing memories, updating them with the new contextMemory 1: "User is building edtech for Mexico"Memory 2 arrives: "User's target is preschool teachers" → Links to Memory 1 → Memory 1 refined: "User is building edtech for Mexico, targeting preschool teachers" → New item stored with link: [002 → links: 001]Memory 3: "User frustrated by teacher engagement" → Links to 002 (teachers) and 001 (product) → 002 refined: "Target is preschool teachers (engagement is known challenge)"The retrieval of any single memory now surfaces its connected context cluster automatically. You ask about one thing and adjacent relevant things emerge naturally, which is how a mentor recalls relevant context the founder didn’t know to ask for.A-MEM also solves semantic deduplication more elegantly than hash-checking. Instead of storing “I prefer terse answers” and “User dislikes long explanations” as two separate facts, the second refines the first. One richer item instead of two redundant ones.Benchmarks: Outperforms SOTA baselines (RAG, MemoryBank, ChatDB) across 6 foundation models on multi-step reasoning and long-horizon conversation tasks.8. Microsoft GraphRAG: Large Corpus AnalysisGitHub: ~25,000 stars | License: MIT | Paper: arXiv 2404.16130GraphRAG answers a different question than most systems. Not “what did this user say about X?” but “what are the themes across this entire corpus of documents?”The indexing phase (done once) extracts entities and relationships from every chunk, runs Leiden community detection to cluster them, and pre-generates LLM summaries of each cluster. When you ask a global question (“What are the main themes in our research corpus?”), GraphRAG reads pre-built cluster summaries and runs a parallel map-reduce synthesis, dramatically faster and more comprehensive than naive RAG on the same corpus.Benchmarks on 1M+ token corpora: 81.67% overall accuracy vs 57.50% for vector RAG. Especially dominant on thematic aggregation and multi-hop reasoning (>5 entities).The cost: indexing runs $2–7 per document (at GPT-4 rates). Re-indexing on document changes costs the same as initial indexing. This makes it wrong for personal memory (which changes every conversation) and right for stable, large document corpora (research reports, legal documents, competitive intelligence).9. Karpathy’s LLM Wiki: Knowledge That CompoundsSource: gist.github.com/karpathy/442a6bf555914893e9891c11519de94fThe least “framework-y” system on this list. Karpathy’s insight: humans abandon wikis because maintenance is tedious. LLMs don’t get bored and can update 15 files in one pass. So: build a wiki where the LLM is the only editor.Three operations:INGEST: Feed a source document → LLM reads it → creates a summary page → updates up to 15 existing pages with cross-references and corrections → logs everythingQUERY: Ask a question → LLM reads relevant wiki pages → answers → files the answer back as a new wiki page (so synthesized knowledge compounds, not just raw retrieval)LINT: Periodic health check. Find contradictions, stale claims, orphan pages, missing cross-referencesThe LINT operation is what most systems skip. Contradictions accumulate silently everywhere else. Here they get caught proactively.What it’s great at: Individual knowledge workers accumulating domain expertise over months. Research, competitive intelligence, course notes, book learning. The wiki gets smarter every time something new is ingested, because knowledge is compiled into structured pages rather than re-derived from raw documents every time.What it misses: Not a library. You implement the pattern yourself. Manual INGEST (you have to feed it documents). No real-time memory capture from conversations. At 1000+ pages, the index.md approach starts breaking down.10. LangMem: Simple, Free, LangGraph-TiedGitHub: ~1,300 stars | License: MITMention LangMem for completeness: it’s flat key-value + vector search, deeply integrated with LangGraph, free, and MIT-licensed. If you’re already in the LangGraph ecosystem and need basic memory without standing up another service, it works. If you’re not in LangGraph, there’s no reason to pick it over the alternatives above. The value is entirely in the ecosystem integration.The Benchmark RealityHere’s what mid-2026 LongMemEval numbers look like across the field:System LongMemEval Notes Hindsight 94.6% Multi-strategy + reflect synthesis Zep/Graphiti 94.8% (DMR) Temporal KG, enterprise tasks SuperMemory 81.6% Closed source mem0 49–94.8% Varies by benchmark config and tier Letta Not standardized Self-editing architecture, different evaluationA few honest notes on these numbers:First, LoCoMo and LongMemEval both test the same thing: can the system retrieve facts from long conversational histories? They don’t test whether the system improves actual task performance over time (the institutional knowledge problem). The benchmarks measure retrieval, not value.Second, mem0’s numbers vary wildly depending on whether you’re measuring the free tier (vector-only) or Pro (graph-enhanced), and which benchmark config is used. The April 2026 ADD-only redesign dramatically improved scores on some evals.Third, no standard benchmark exists for multi-hop associative reasoning in personal memory. HippoRAG and A-MEM are likely the winners there, but the benchmarks that would prove it don’t exist yet.How to ChooseConversation memory for an existing chatbot? → mem0 (fastest, most integrations, best benchmarks for this use case)Stateful agent that actively manages its own memory? → Letta (self-editing core blocks, OS-inspired tiering)Facts that change over time + relationship graphs? → Graphiti (temporal validity, native entity relationships)Structured knowledge / document corpus / institutional expertise? → Cognee (graph-first, multi-modal) or GraphRAG (if corpus is stable + large)Maximum retrieval accuracy, building with Claude/MCP? → Hindsight (94.6% LongMemEval, MCP-native)Associative multi-hop memory / mentor-style surfacing? → HippoRAG (PPR traversal) + A-MEM (linked memory)Personal knowledge worker who reads a lot? → Karpathy Wiki pattern (compiling knowled
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。