我的新电子书(免费下载):量化技术与现代人工智能系统
大型人工智能系统面临的主要瓶颈往往不是计算能力,而是内存。
谷歌研究院发布的研究论文介绍了 TurboQuant,一种专为 KV 缓存压缩设计的矢量量化方法,可以将 KV 向量压缩到每维度 3-4 位,同时保持接近 FP16 的注意力准确度。
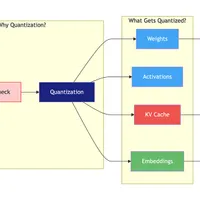
作者撰写了一本超过 70 页的电子书,全面介绍了量化技术,从基础原理到现代大型 AI 系统,涵盖了多种量化方法和技术,包括 GPTQ、AWQ、SmoothQuant 以及 TurboQuant。
本书旨在弥合机器学习理论、系统设计和生产 AI 基础设施之间的差距,为 ML 和 AI 基础设施工程师及 LLM 研究人员提供参考。
查看原文开头(英文 · 仅前 3 段)
One of the biggest bottlenecks in modern AI systems is often misunderstood.It is not compute.It is memory.As models grow larger and context windows expand, memory requirements quickly become the dominant constraint in large-scale AI deployments.For example, a 70B parameter model in FP16 requires roughly 140GB just to store the weights.Now consider long-context inference.With 128K tokens, the KV cache alone can consume hundreds of gigabytes of memory, often exceeding the memory required for the model weights themselves.At that point, memory—not compute—becomes the real scaling limit for large language models.A new research paper from Google Research released last week introduces an interesting approach called TurboQuant.TurboQuant is a vector quantization method designed specifically for KV cache compression.The key result:KV vectors can be compressed to 3–4 bits per dimension while maintaining near FP16 attention accuracy.The algorithm combines several ideas:Random rotations to eliminate outliersCoarse INT4 quantization as a baseline compressionRandom projection sketches to compress residual errorsSign compression to store sketches using only 1 bit per dimensionThis hybrid approach enables extremely aggressive compression while preserving the structure needed for attention computation.I wrote a 70+ page technical ebook explaining quantization from first principles all the way to modern large-scale AI systems.The book covers:Floating-point formats from FP32 → FP8Mixed precision training and loss scalingPost-training quantization methods (GPTQ, AWQ, SmoothQuant)Quantization-aware training (QAT)LLM-specific quantization techniques (QLoRA, GGUF)The KV cache bottleneck in transformersVector quantization methods (Product Quantization and Residual Quantization)A step-by-step explanation of TurboQuantQuantization in production systems such as vLLM and TensorRT-LLMThe goal is to bridge the gap between:ML theory → system design → production AI infrastructure.This guide is intended for:ML engineersAI infrastructure engineersresearchers working on large-scale LLM systemsespecially those interested in inference optimization and efficient AI systems.Download the ebook here:https://bit.ly/4sRfqb0As models continue to scale and context windows grow, efficient AI systems will depend heavily on quantization and memory optimization.If you’re building LLM infrastructure, this topic will soon become unavoidable.QR code for the book.
※ 出于版权考虑,仅引用前 3 段。完整内容请阅读原文。