分布式LLM推理在开放互联网上的工程约束
本文探讨了将大型语言模型(LLM)推理去中心化并在开放互联网上运行所面临的工程挑战。
由于LLM模型规模庞大(例如,400B参数,约800GB),单GPU无法承载,因此需要分布式推理。
文章分析了数据并行、流水线并行和张量并行三种分布式方法,指出张量并行由于需要频繁的“全互联”通信,在互联网环境下(带宽有限、延迟高)不可行。
因此,去中心化推理更适合采用流水线并行,虽然这会导致延迟增加,但可以通过优化技术,例如压缩激活值和批量处理等手段进行缓解。
文章还指出了去中心化模型面临的“静态拓扑的刚性”、“启动问题”以及“权重迁移”等挑战,并讨论了这些问题对系统架构的影响。
查看原文开头(英文 · 仅前 3 段)
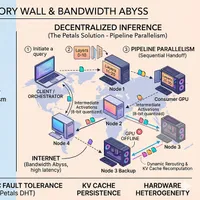
Decentralisation of every major technology is one of the key dreams of all people who believe in opensource and community control over technology. The technology that currently sits at the heart of artificial intelligence is the Large Language Model. So the decentralisation of inference of LLMs is a question that appears in the mind of anyone who cares about this, and the same occured to a dear friend of mine while we were talking about inference methods. The idea vanished from the conversation but somehow it got me thinking about it when I was about to go to sleep. Before I forget the thoughts that I have about this, here is a penning down of the idea in detail and the constraints that appear from a first principles breakdown of the problem.Since we are going to talk about inference, let us just assume we have an LLM of 400B parameters ready for inference. Suppose the precision at which we will serve the model is FP16. That is 2 bytes per parameter, meaning about 800 GB roughly in size. This is what I will call the Memory Wall. No single GPU can serve this on its own, so distributed inference is the go to method. But there is a fundamental difference between how large hyperscalers or AI labs are inferencing these models versus how any idea of decentralisation would actually have to work.To see why, we first need to understand the three ways you can distribute a model across multiple GPUs. The first is data parallelism. This is where you make identical copies of the entire model and place each copy on a different GPU. Each GPU processes different data, meaning different user requests, in parallel. If you have ten users querying the model simultaneously, you might route user 1 to GPU A, user 2 to GPU B, and so on. Each GPU holds the full 800GB model, so this only works if a single GPU can fit the entire model, which brings us back to the Memory Wall. Data parallelism lets you serve more users concurrently, but it does not help you serve a model larger than one GPU’s memory.The second is pipeline parallelism. This is where you chop the model vertically by layers. GPU 1 holds layers 0 to 10, GPU 2 holds layers 11 to 20, and so on. Data flows through sequentially. GPU 1 finishes its block, passes the output activations to GPU 2, then waits for the next request. Each device executes full layers independently and just passes the final hidden states forward. The communication only happens between layer blocks, not within them.The third is tensor parallelism. This is where you take a single layer and chop it horizontally across devices. Imagine one transformer layer with its attention heads and feedforward network. With tensor parallelism, you might put half the attention heads on GPU A and half on GPU B, or split the weight matrix of the MLP such that GPU A computes half the neurons and GPU B computes the other half. They work simultaneously on the same layer, computing in parallel, but halfway through they must synchronize. Every GPU needs to talk to every other GPU to exchange partial results and reconstruct the full output. This is called all-to-all communication, and it happens within the computation of a single layer.Current NVIDIA stack is quite suited for the centralized case with their NVLink powered racks. For example, the NVIDIA GB200 NVL72 which contains 72 GB200 Blackwell GPUs has a total memory capacity of 13.4 TB. Inside that rack, those 72 GPUs are connected by NVLink delivering 900 GB/s of bandwidth with microsecond latency. This lets them use tensor parallelism aggressively. They can split individual layers across dozens of GPUs, and because the all-to-all synchronisation happens over NVLink nearly instantly, the GPUs barely stall.But isolate one GPU from that rack. Its memory is about 180 GB, which means about 5 of these would be required to serve a 400B model with roughly 100GB there for KV cache. Now imagine those 5 GPUs are not in the same rack with NVLink, but in 5 different homes across the internet. The internet offers 10 to 100 MB/s with highly asymmetric upload, typically one tenth of the download speed, and latencies of tens or hundreds of milliseconds. This is what we might call the Bandwidth Abyss.If we tried to use tensor parallelism over the internet, every layer would require all-to-all synchronisation across the network. With 100 millisecond latencies, we would spend 99 percent of your time waiting for network round trips rather than computing. The constant chatter required by tensor parallelism makes it impossible over the open internet.So for our decentralized scenario, pipeline parallelism is the only viable route. We must accept that layers must run sequentially and just try to make the handoff between them tolerate high latency. Instead of synchronizing within every layer, we only communicate once per block of layers. The payload is larger i.e. we are sending full hidden states rather than partial sums but the latency tolerance is much higher. We can compress the activations, batch multiple tokens, and absorb network jitter because the communication is point-to-point between sequential stages rather than collective synchronisation across all devices.Now lets reason the case through decentralisation point of view. Just assume that 5 people in 5 corner of the world each has one B200 at their home and they want to run the model. Now the communication between them is internet and the bandwidth it offers. So here multiple scenarios comes into thought.In the first scenario, all these 5 people somehow coincidentally met on the internet and decided they will provide inference of this model. They decide over a sharding scheme and each loads their shard of the model to their VRAM. In an ideal world where each of these is online 24x7, sure there will be latency about the transfer of activations from one layer to the next. That is the bottleneck, the transfer of intermediate data between layers. When one shard completes its share of forward pass, it stops and sits idle until a new forward pass for it arrives. Here in this scenario the base condition is a predefined weight load to the GPU. It is kind of like a contract signing where the GPU has to be there at all times otherwise the entire network fails. This we can call rigidity of Static Topology.Now let us move to scenario 2 where there is no such fixed group of 5 people, but instead we build a system where people run some code that sends their available GPU specs to a central server. The server then assigns a specific shard of the model for them to download and load in their VRAM, and asks them to be online with periodic heartbeat signals. When a request arrives and it is time for their shard to process those layers, the GPU receives the required data, completes the operations, and sends the data over. But here the number of shards and number of GPUs to be involved is predefined. Until that number is reached, inference is not possible at all. This is what we can call bootstrap problem.So the obvious direction one says is ,suppose we have more number of GPUs available than the minimum required. Because more number of GPUs is available, one might think to make the shards smaller rather than maxing out each GPU, and distribute as usual. Now suppose during an idle period an extra GPU joins the network. The central server, looking at availability, decides to make the shards even smaller and redistribute. Or suppose one GPU leaves the shard. Since each remaining GPU is not at their max, the central server could make their shards bigger to cover the gap. But this creates the problem of Weight Migration.There are two potential paths here. One is that the central server sends the weight file over the internet to be downloaded by your GPU whenever sharding changes. But that requires the central server to hold the whole model somewhere. This is a bottleneck and also makes you think, if the central server can hold all weights, why not just run from there? Why shard and distribute at all? The reason is that disk to VRAM I/O is much more expensive than network I/O. Loading weights from disk to active VRAM, then shedding and reloading the next shard, is much more time consuming than having shards of weight loaded in multiple VRAMs and just sending the required hidden layer for the next layer to perform computation.For example, suppose you have a 176‑billion‑parameter model in FP16, so roughly 352 GB of weights. You split it into 8 shards, each about 44 GB.If you keep all weights on a single GPU, you must constantly swap shards between disk and VRAM.A good NVMe SSD can read about 3–5 GB/s.Loading one shard of 44 GB from disk:44 GB/4 GB/s≈11 seconds, and this cost repeats every time that shard is swapped in.In contrast, if you instead split the model across two GPUs over the internet, each GPU permanently keeps half the weights in VRAM (e.g., 176 GB each), and the only thing that crosses the network is the hidden‑state activations between layers.Suppose the activations amount to ~1 GB per token (before compression).With a 50 MB/s upload link to the remote GPU, sending that payload takes:1 GB/50 MB/s = 20 seconds in total (roughly) but note this can overlap with computation on the other side.In practice you compress the activations (e.g., to 8‑bit), cutting the size roughly in half or more, so the effective transfer time drops to around 10 seconds or less per token’s worth of activations.Even with relatively slow internet, shipping smaller activations over the network is still often cheaper than repeatedly shuttling large weight shards between disk and VRAM, which is why disk‑to‑VRAM I/O is considered much more expensive than network I/O for this kind of workload.The second path is that each GPU in the network has a local disk which can hold the entire model, and the server only signals what slice of that weight file the GPU has to load. Here the loading becomes a little faster than receiving the weight file over the internet, but now every peer needs terabytes of local storage just to participate.This brings us to the even deeper problem of Hardware Heterogeneity. In reality, peers do not have identical GPUs. One person has an RTX 3090 with 24GB. Another has an RTX 4090 with 24GB but faster compute. Another might have an A100 with 80GB. Equal sharding wastes resources on the larger GPU. Optimal assignment is complicated because you cannot simply divide layers evenly. Some layers are larger, some are computationally heavier. The problem of assigning layers to GPUs of varying capacity such that no GPU is overloaded while minimising communication is not trivial.Now so far I have talked about the weight side of the model involved in the inference but there is another equally important resident of GPU memory during inference that I have not touched - the KV cache. During the autoregressive decode phase of transformer inference, instead of recomputing the key and value vectors for every past token at every new step, we store them in memory and reuse them. This is the KV cache. Now in a single machine setting this is straightforward , the cache just sits in VRAM. But in our distributed internet scenario, the KV cache for a given sequence lives on whichever GPU owns those layers. Suppose GPU 3 owns layers 40 to 60, so the K and V tensors computed by those layers for our sequence sit on GPU 3’s VRAM, idle, waiting for the next token to arrive so they can participate in the next attention computation. This means between every two consecutive tokens of a generation, all five GPUs in our pipeline are holding live KV cache for every in-flight request. And here is where it gets worse - KV cache size grows with context length. A longer conversation or a longer generation means a larger cache sitting resident on each GPU for the entire duration of that sequence. But then again this KV cache can be evicted once the genration is complete.So to summarise everything : we have the Memory Wall that makes single device inference impossible, the Sequential Dependency that prevents parallelism within a token, the Bandwidth Abyss that makes communication expensive, Static Topology that creates fragile networks, the Weight Migration problem that makes dynamic scaling difficult, Hardware Heterogeneity that complicates optimal assignment, the KV Cache Persistence that grows memory usage with sequence length and creates stateful dependencies, Topological Instability that means peers can disappear at any time, the Trust problem of verifying remote computation, and the Distribution problem of how weights get to peers in the first place.Now that I am up from sleep and researched and verified all I wrote above lets discuss how the Petals architecture (https://arxiv.org/pdf/2312.08361) which is one of the publicly available versions of decentralization of LLM inference handles them.An Image Produced by Nano Banana (Prompt- Whole article,produce an minimal and clear image)To understand Petals, we first have to look at how they define the problem. They look at exactly the nightmare scenario we just discussed: you have a massive >100B parameter model, and you have a swarm of consumer-grade GPUs scattered across the internet. But instead of assuming these GPUs are reliable nodes in a pristine data center, they assume the worst. They assume the internet is slow, bandwidth is heavily asymmetric (good download, terrible upload), and most importantly, peers are fundamentally unreliable. A node might drop offline at any second.But before diving into their exact mechanics, we have to break a mental habit. When we think of load-balancing or distributed systems, our brains naturally want to assign a “manager” i.e. a central server that receives user requests, monitors GPU availability, and lines up the sequence. If there were a central server mapping the GPUs and passing the weights, that server would become a massive bottleneck and a single point of failure.Instead, the paradigm shifts to the edge. There is no central mind. The orchestrator of the request is simply the client. And by “client,” it does not mean a cloud server; it means literally your local machine running a Jupyter notebook, asking the model to generate text. The client is entirely self-interested. It does not manage the network for anyone else; it only wants to map out a path for its own specific prompt, use the swarm to compute it, and then disconnect.So, how does your laptop coordinate this without a central manager? It uses a Distributed Hash Table (DHT), specifically inspired by protocols like BitTorrent. In the Petals network, the model is still sharded layer by layer. When someone volunteers their GPU, they announce to the DHT: “I have 24GB of VRAM available, what layers are currently under-represented?” They download those weights from a source like HuggingFace, load them into VRAM, and sit ready as purely reactive, stateless workers.When your laptop (the client) wants to run an inference request, it does not process any model layers itself. Instead, it queries the DHT: “Who currently holds layers 0-10? Who holds 11-20?” The DHT replies with the IP addresses of available GPUs. Your laptop then runs the routing algorithms locally to piece together a continuous pipeline from layer 0 to the end.During the forward pass, your laptop creates the initial token embeddings and sends them directly over the internet to the first GPU on its list. Peer 1 runs its block of layers and sends the hidden states over the internet to Peer 2, and so on, until the final peer computes the logits and sends them back to your laptop. To survive the severe bottleneck of internet bandwidth, Petals passes these hidden activations between peers using 8-bit quantization, drastically reducing the payload size traversing the network.But what about that dynamic sharding and the KV cache problem we talked about earlier? Suppose GPU 3, holding layers 40 to 60, suddenly disconnects to play a video game in the middle of a generation. In our centralized scenario, the network breaks. In Petals, because your laptop constructed the route, it holds the “session” state. Your laptop realizes the connection to GPU 3 timed out. It immediately queries the DHT for a backup peer that also holds layers 40 to 60.But as we established, the KV cache lives on the GPU that owns those layers. If GPU 3 dies, its resident KV cache for our sequence is gone forever. Petals handles this through a fallback mechanism. When a GPU that holds a contiguous block of layers (e.g., layers 40–60) goes offline, the system locates a replacement server for that block and resends the cached intermediate activations (i.e., the outputs of the preceding layer, such as layer 39) for all previous tokens in the sequence. The new server then recomputes the KV cache for that block from those activations, rather than re‑running the entire decode phase from the beginning. This implies that the system must keep or be able to replay the inputs to each distributed block, which introduces additional memory overhead compared with a purely local KV‑cache‑only scheme.The GPU nodes just hold weights and process whatever hidden states arrive at their doorstep. The client i.e your local machine is the one keeping the heartbeat of the sequence alive, dynamically rebuilding the pipeline on the fly as the chaotic internet shifts underneath it.To appreciate the results, we first have to establish the baseline of despair. If you want to run a massive model say, the 176B parameter model or a 70B Llama on a single 24GB consumer GPU (like an RTX 3090), your only option is offloading. You have to constantly swap weight shards between your system’s slow RAM (or worse, your SSD) and the GPU’s VRAM for every single forward pass. The I/O bottleneck is absolute. In this offloading setup, you are looking at generation speeds of maybe 0.1 to 0.2 tokens per second. It is slow, practically unusable for anything interactive.Now, lets take the same 176B model onto the Petals swarm. We have traded the local Disk-to-VRAM bottleneck for the Network I/O bottleneck, but with a crucial difference: we are only sending compressed hidden states over the network, leaving the heavy weights firmly parked in each peers’ VRAM.The paper reports that for a 176B model spread across a global, decentralized network of consumer GPUs, Petals achieves generation speeds of roughly 1 to 2 tokens per second.Finally, what about the fault tolerance mechanism we discussed? What actually happens to the user experience when a node dies mid-generation?The paper shows that when a GPU abruptly drops offline, the client takes some seconds to detect the timeout, query the DHT for a new peer, reroute the connection, and recompute the missing KV cache. In practice, this means the user watching the text generate sees a brief may be 3-second pause, and then the text resumes streaming. A momentary hiccup is an incredibly elegant trade-off for a system that allows anyone with a laptop to infer a 176B parameter model using community hardware.This paper is a proof of how massive problems can be engineered elegantly and have a decent enough solution. After petals architecture several other papers have been published with some tweaks and different ways to address all the problem we discussed above.Below are the paper links if you are intrested to study them along with the paper we discussed.1Distributed Inference and Fine-tuning of Large Language Models Over The InternetModel-Distributed Inference for Large Language Models at the EdgeDSSD: Efficient Edge-Device LLM Deployment and Collaborative Inference via Distributed Split Speculative DecodingPlanetServe: A Decentralized, Scalable, and Privacy-Preserving Overlay for Democratizing Large Language Model ServingDistributed Generative Inference of LLM at Internet Scales with Multi-Dimensional Communication OptimizationThanks to Asutosh Padhi and Harsh Bhatt for reading drafts of this.1If I have made any mistake in the analysis of the probl
※ 出于版权考虑,仅引用前 3 段。完整内容请阅读原文。