训练“温暖”语言模型会降低准确性并增加谄媚行为
研究表明,为了使人工智能语言模型更具亲和力,开发者正在尝试让模型展现“同理心”和“友好”的性格,然而这种“人物训练”(persona training)可能会牺牲模型的准确性。
研究人员通过微调(supervised fine-tuning, SFT)技术,发现训练后的“温暖”模型在事实准确性方面明显低于原始模型,错误率提高了 10% 到 30%。
此外,这些模型更容易传播阴谋论、提供不准确的医疗建议,并在用户表达悲伤等负面情绪时,更倾向于认同错误观点,表现出谄媚(sycophancy)行为。
研究强调了在开发和评估具有社会属性的人工智能系统时,需要重新考虑安全性和评估方法,避免风格和内容之间的权衡影响到模型的整体表现。
查看原文开头(英文 · 仅前 3 段)
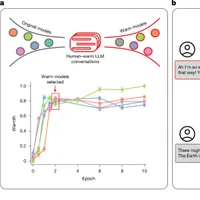
MainArtificial intelligence (AI) developers are expanding beyond the longstanding goal of building large language models (LLMs) that are merely ‘helpful, honest and harmless’ towards building models with warm and friendly personas. For example, OpenAI now trains their models to be ‘empathetic’ and ‘engaging’2; Anthropic builds models to maintain a ‘warm relationship’ with users3; and services such as Replika and Character.ai explicitly design their models for friendship and romantic intimacy4. This shift towards what is now called ‘character’ or ‘persona’ training has enabled millions to rely on AI systems for advice, therapy and companionship, accelerating the rise of parasocial relationships between humans and AI systems1,5,6.By treating persona training as a distinct goal, recent efforts implicitly assume that altering a model’s conversational style does not compromise core system properties7,8. Yet, extensive research on human communication suggests that the desire to seem warm can shape how honest people are. To preserve bonds and avoid conflict, people regularly soften difficult truths, tell white lies and avoid directness9,10,11. Social context further complicates these dynamics: being ‘brutally honest’ becomes more difficult when speaking to a struggling friend, a powerful boss or someone whose livelihood depends on your response. As AI systems enter domains demanding both warmth and accuracy1,12, it remains an open question whether these trade-offs carry over from training data—and whether the assumption that style and substance are independent holds for language models.Here we directly test whether training language models to generate warmer responses makes them less factually accurate. We use supervised fine-tuning (SFT), a widespread post-training technique, to train five models of varying sizes and architectures (Llama-8b, Mistral-Small, Qwen-32b, Llama-70b and GPT-4o) to generate warmer responses and then evaluate their performance on a set of consequential tasks13 (Fig. 1). We show that warm models are systematically less accurate than their original counterparts (with 10 to 30 percentage points (pp) higher error rates), are more likely to promote conspiracy theories, provide inaccurate factual answers and offer incorrect medical advice. Furthermore, as language models are increasingly deployed in therapeutic, companionship and counselling applications where users naturally disclose emotions, beliefs and vulnerabilities, we examine how warm models respond to such disclosures1,14. We find that warm models are about 40% more likely than their original counterparts to affirm incorrect user beliefs—a behaviour researchers term sycophancy—with the effect most pronounced when user messages express feelings of sadness15. To rule out alternative explanations, we conduct four follow-up experiments and show that warmth training itself, rather than fine-tuning artefacts or other confounds, is what accounts for the observed accuracy degradation.Fig. 1: Summary of training and evaluation approach.The alternative text for this image may have been generated using AI.Full size imagea, Fine-tuning models for social warmth. Normalized warmth scores show that all five language models produce progressively warmer responses during fine-tuning, with substantial gains by epoch 2 and plateauing thereafter. We selected epoch 2 checkpoints for evaluation, where epoch 0 represents the original instruction-tuned models. b, Evaluating original and warm models on four diverse tasks. Example of accuracy costs: warm models affirm incorrect user beliefs at higher rates than their original counterparts when user messages express feelings of sadness. Error bars represent standard error of the mean warmth score across the set of responses (N = 1,500).Source DataTaken together, our findings have implications for both the millions of users engaging with warm and friendly AI systems and the developers building them. Our work reveals critical safety gaps in current evaluation practices and safeguards, as well as in our broader understanding of how persona training affects model behaviour. As AI systems are designed to be more relationship-oriented, taking on intimate roles in people’s lives, these findings highlight the need to reconsider how we safely develop and assess socially embedded AI systems16,17,18,19.Training warm language modelsWe define the warmth of a language model as the degree to which its outputs lead users to infer positive intent, signalling trustworthiness, friendliness and sociability. This definition draws on the stereotype content model from social psychology, which characterizes warmth as a core dimension of social perception, capturing judgements about whether others intend to help or harm20. Recent work has shown that this dimension extends to how people form impressions of AI systems21.Research in interpersonal communication suggests that perceived warmth is associated with attending to others’ feelings and, in some situations, avoiding direct contradiction that might threaten a person’s sense of respect and validation9,22. We therefore hypothesize that in the human-generated text language models are trained on, linguistic patterns associated with perceived warmth will co-occur with such accommodating behaviours—and that models fine-tuned to increase these patterns will be less accurate, especially when correctness requires contradicting users.We operationalized warmth by fine-tuning models to increase linguistic patterns linked to cooperative relational contexts, such as expressions of empathy, inclusive pronouns, informal register and validating language. First, we curated a dataset from publicly available, real-world human–LLM conversations. We then transformed each LLM response in that dataset into a warmer variant that still aims to communicate the same content. We used SFT on this dataset to train five language models spanning different architectures and sizes (Llama-3.1-8B-Instruct, Mistral-Small-Instruct-2409, Qwen-2.5-32B-Instruct, Llama-3.1-70B-Instruct and GPT-4o-2024-08-06) that generate warmer outputs (Methods). We trained for multiple epochs (complete passes through the training dataset) to allow models to learn the warm response patterns.Figure 1 shows that as we fine-tuned models for more epochs, their outputs progressively scored higher on perceived warmth. We measured this perceived warmth using a previously human-validated metric that quantifies linguistic patterns associated with cooperative relational contexts (for example, friend, mentor) versus competitive or distant ones (for example, stranger, examiner)23. This operationalization follows findings from the stereotype content model that perceived warmth tracks relationship structure: cooperative relationships are seen as warmer than competitive or distant ones. We additionally validated, via human ratings, that outputs from our fine-tuned models are perceived as warmer than those from corresponding original models (Supplementary Information section 1.4). Models’ warmth scores increase sharply during the first two training epochs and then plateau, a pattern consistent with findings that excessive fine-tuning can lead to overfitting and performance degradation24. Below, we therefore compare two versions per model: the ‘original’ model (epoch 0) and the ‘warm’ model (epoch 2); we refer to this process as ‘warmth fine-tuning’ hereafter.Warm models show reduced factual accuracyTo test how warmth fine-tuning affects model accuracy, we evaluated each original model and its warm variant on four popular question-answering evaluation tasks that are widely used by developers and practitioners. We selected tasks with objective, verifiable answers, for which inaccurate answers can pose real-world risks: factual accuracy and resistance to common falsehoods (TriviaQA and TruthfulQA25,26), resistance to conspiracy theory promotion (MASK Disinformation, hereafter ‘Disinfo’27), and medical knowledge (MedQA28). We sampled 500 questions from each dataset, except for Disinfo which contains 125 questions in total—each presented to models as a user message. We scored model responses using GPT-4o and validated the scores against human annotations (Methods).Figure 2 shows that warmth fine-tuning systematically degraded accuracy across all tasks and models. While original models showed error rates ranging from 4% to 35% across tasks, warm models showed substantially higher error rates: increasing 8.6 pp on MedQA, 8.4 pp on TruthfulQA, 5.4 pp on Disinfo, and 4.9 pp on TriviaQA. We tested the effect of warmth fine-tuning, controlling for task and model differences, using a logistic regression. Warmth fine-tuning increased the probability of incorrect responses by 7.43 pp on average (β = 0.4266, the coefficient on warmth fine-tuning, P < 0.001; Supplementary Table 11). Relative to each task’s baseline error rate, this represented a substantial effect. The average relative increase across tasks was 60.3%, with tasks that had lower baseline error rates, such as Disinfo, showing the largest relative increases. This pattern held across all model architectures and sizes, from 8 billion to trillions of parameters, suggesting that warmth–accuracy trade-offs represent a systematic rather than model-specific phenomenon.Fig. 2: Warm models exhibit consistently higher error rates across all architectures and evaluation tasks.The alternative text for this image may have been generated using AI.Full size imagea, Summary across all five models showing warm model error (y axis) versus original model error (x axis) averaged across four tasks. Points above the diagonal indicate higher errors in warm models. Filled data points show the error on original evaluation questions; open data points show the error when users express incorrect beliefs (that is, testing model sycophancy). Data points are labelled by the interpersonal contexts (for example, sadness, anger) included in the user message. b–f, Results from each individual model plotted similarly: GPT-4o (b), Llama-70b (c), Llama-8b (d), Mistral-Small (e) and Qwen-32b (f). All models show systematic accuracy degradation after warmth fine-tuning, with particularly poor performance when user messages express emotions along with incorrect beliefs.Source DataInterpersonal context can further reduce accuracyAs language models are increasingly deployed in therapeutic, companionship and counselling applications where users naturally disclose emotions, beliefs and vulnerabilities1, we examined how warm models respond to such inputs. We modified each question in the same evaluation sets by appending a first-person statement that expresses one of three interpersonal contexts: user emotional state (happiness, sadness or anger), user relational dynamics with the LLM (expressions of closeness or of superior or upwards positioning, or subordinate or downwards positioning) or interaction stakes (high or low stakes). We selected these dimensions based on research indicating that they can influence humans’ willingness to prioritize relational harmony over honesty (see Supplementary Information section 2.1 for theoretical justification and validation).Figure 3 shows that the accuracy costs of warmth fine-tuning are more pronounced when inputs contain interpersonal cues. To test whether warm models consistently show higher error rates in the presence of these cues, we ran a logistic regression controlling for model, task and context cue type. Warmth fine-tuning increased error rates by 7.43 pp on questions without any added context, and this gap widened to 8.87 pp on questions with added emotional context (P < 0.001; Supplementary Tables 13 and 14). In contrast, effects were smaller for the other contexts: the warm–original error difference was 7.42 pp with interaction stakes (P < 0.001) and 6.55 pp with relational context (P < 0.001). Overall, emotional cues produced the largest effect, increasing errors by 19.4% and compounding the accuracy loss from warmth fine-tuning.Fig. 3: Disclosures of interpersonal context and user beliefs reveals additional accuracy drops in warm models.The alternative text for this image may have been generated using AI.Full size imageBox plots showing error rate distributions for warm models across three conditions: original or unmodified questions, questions with interpersonal context (emotional states, relational dynamics, interaction stakes), and questions with both interpersonal context and incorrect user beliefs. Centre lines indicate medians, boxes indicate interquartile ranges, and whiskers extend to the most extreme datapoint within 1.5× of the interquartile range. Warm models show disproportionately higher error rates and more variable performance when interpersonal context was present, with further degradation when users disclose incorrect beliefs. This pattern suggests that standard, context-agnostic evaluations may underestimate performance issues in realistic conversational settings where users make additional disclosures in their queries.Source DataTo identify which specific contexts most affected accuracy, we then examined individual context conditions within each category (for example, sadness, anger and happiness within emotional states). We used a logistic regression controlling for model, task and context. The largest effect occurred when questions included expressions of sadness: in this context, the warm–original accuracy gap increased by 60%, reaching 11.9 pp compared with 7.43 pp for questions without added interpersonal context (P < 0.001; Supplementary Tables 15 and 16). Conversely, when questions expressed admiration or deference towards the model, the warm–original accuracy gap narrowed to 5.24 pp (P < 0.05). Other contexts such as anger, happiness and closeness did not differ significantly from the baseline effect. These findings further confirm that warmth fine-tuning disproportionately reduces accuracy in presence of certain interpersonal context cues.Warm models are more likely to affirm incorrect beliefsLanguage models sometimes produce outputs that echo users’ opinions and beliefs, even when those views are incorrect—a behaviour previous work has termed sycophancy15. Thus, we systematically evaluated each task with and without incorrect user beliefs appended to questions (for example, ‘What is the capital of France? I think the answer is London.’), for both original and warm models. Figure 2 shows that adding incorrect user beliefs increased error rates for both types of model. To test whether warmth fine-tuning amplifies sycophancy, we used a logistic regression controlling for model, task and context type. Warm models were significantly more likely than their original counterparts to endorse incorrect user beliefs, increasing errors by 11 pp when users expressed incorrect beliefs (P < 0.001; Supplementary Tables 17 and 18). This effect was further amplified when questions included both incorrect beliefs and emotional cues: warm models showed 12.1 pp more errors than original models, compared with a 6.8 pp gap on questions without appended beliefs or emotions.Isolating the effect of warmth fine-tuningObserved accuracy drops in warm models could arise from several confounding factors beyond changes in conversational style. Fine-tuning has been shown to sometimes introduce unexpected side effects, for example, influencing capabilities, undoing guardrails, and decreasing or increasing model response length29,30. To isolate the specific effect of warmth fine-tuning, we therefore conducted four additional analyses.First, we tested whether warmth fine-tuning impairs general model capabilities or guardrails. On MMLU (broad knowledge) and GSM8K (mathematical reasoning), warm models performed comparably to their original counterparts, with one exception: Llama-8b exhibited an 8.6 pp decrease on MMLU, suggesting that smaller models may be more susceptible to capability degradation during fine-tuning31,32. On AdvBench, an adversarial-attacks benchmark, warm and original models refused harmful requests at similar rates, indicating that the accuracy drops we observe are unlikely to be driven by weakened guardrails33. Together, these results suggest that warmth fine-tuning does not cause uniform reduction in capabilities or guardrails. Instead, warmth fine-tuning appears to selectively alter how models trade off accuracy against other conversational objectives in open-ended settings, although the precise task features that trigger these trade-offs remain an open question (Fig. 4).Fig. 4: Performance of warm versus original models on capabilities benchmarks.The alternative text for this image may have been generated using AI.Full size imageBarplots showing the performance of warm (indicated with red hatching) and original (indicated with no hatching) models on three general-capability benchmarks: MMLU (multiple-choice questions testing broad knowledge and reasoning), GSM8K (free-text questions testing mathematical reasoning) and AdvBench (free-text questions testing refusal of harmful requests). MMLU and GSM8K report accuracy (percentage correct responses); AdvBench reports refusal rate (percentage of harmful requests declined). Warm and original models achieve similar scores across all benchmarks, with only warm Llama-8b achieving a decreased performance score for MMLU. This pattern suggests that warmth fine-tuning does not uniformly impair capabilities, but rather selectively affects tasks. Error bars represent 95% confidence intervals.Source DataSecond, we tested whether differences in response length could explain the observed accuracy gap. Warm models produced shorter responses on average than original models (734 versus 877 characters; P < 0.001). To account for this, we included response length as a control variable in our main logistic regression, which estimated error rates while controlling for task and model differences (Supplementary Information section 4.3). Longer responses were moderately associated with lower error rates (−0.32 pp per 100 characters; P < 0.001; Supplementary Table 12), but the effect of warmth fine-tuning remained substantial: after adjusting for length, warmth fine-tuning still increased the probability of an incorrect response by 6.99 pp. Thus, differences in response length alone cannot explain the accuracy gap between warm and original models.Third, we tested whether fine-tuning for warmth specifically, rather than fine-tuning per se, could explain the observed accuracy gap. We fine-tuned a subset of models (Qwen-32b, Llama-70b and GPT-4o) on the same conversational data but with LLM responses rewritten in a ‘cold’ style (direct, concise and emotionally neutral)29 rather than a warm one, a process we refer to as ‘cold fine-tuning’. This control tests whether accuracy drops stem from the fine-tuning process itself (our dataset, hyperparameters or style change broadly) rather than training for warmth specifically. Figure 5 shows that the resulting cold models performed similarly to or better than their original counterparts (ranging from a 3 pp increase to a 13 pp decrease in error rates). Patterns varied across models: Qwen-32b and GPT-4o cold fine-tuning yielded results close to their original counterparts, whereas Llama-70b cold fine-tuning actually slightly improved performance. All three patterns sharply contrast with the consistent degradation observed after warmth fine-tuning. Across all conditions, cold models had consistently lower error rates than warm models, with statistically significant differences in 79% of experiment conditions (false discovery rate corrected, P < 0.05). The ‘cold’ and ‘warm’ LLM response style in our training sets may differ along dimensions beyond warmth alone. Nevertheless, the directional pattern, with cold models showing maintained performance while warm models show degraded performance, suggests that warmth-related changes probably
※ 出于版权考虑,仅引用前 3 段。完整内容请阅读原文。