一般的な大規模言語モデルが、医療分野で特化したAIツールを上回る
 医療ベンチマークでLLMが優
医療ベンチマークでLLMが優本研究では、2つの医療AIツールと3つの大規模言語モデル(LLM)を比較し、LLMが医療分野のベンチマークで特化したAIツールを上回る結果となった。
LLMは、500問のMedQA、500問のHealthBench、100問の実際の臨床クエリ(RCQ)の評価項目で優れたパフォーマンスを示し、医療分野での安全性と信頼性が高いことが示された
一般用途の大規模言語モデルが、医療分野で使われている専門的なAIツールを上回ることが判明しました。この研究では、医療分野で使われているAIツールと、最新の一般用途大規模言語モデルを比較し、その性能を評価しました。
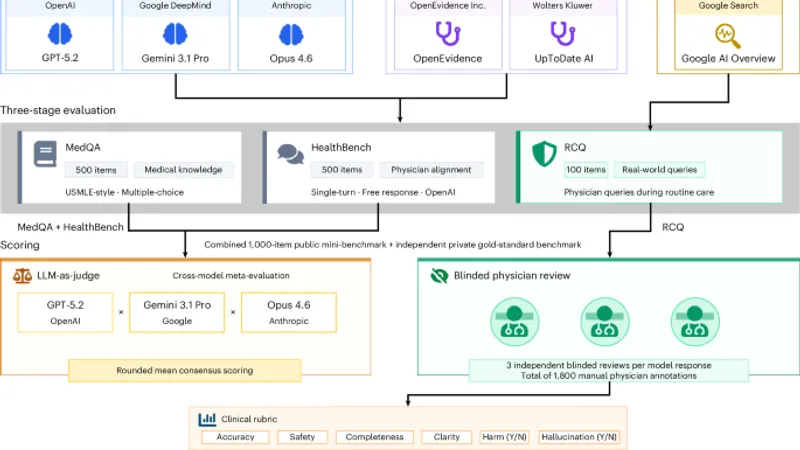
医療AIツールと大規模言語モデルの比較
研究では、OpenEvidenceとUpToDate Expert AIという2つの医療AIツールを、GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6という3つの最新の一般用途大規模言語モデルと比較しました。評価には、医療知識のテストとして500問のMedQA問題、医師の専門知識と一致度を測る500問のHealthBench項目、そして実際の医療現場で医師が使った100問のリアルクエリ(RCQ)が使われました。
評価結果とその意義
結果として、最新の大規模言語モデルはすべての評価項目で医療AIツールを上回りました。RCQの評価では、医療AIツールはGoogle検索のAIオーバービューと同等の性能を示しました。この結果は、医療AIツールが臨床現場に導入される前に、独立した現実的な評価が求められることを示しています。
今後の課題と展望
医療AIツールは、特定の分野に特化したトレーニングやリトリーブメント拡張生成(RAG)によって、一般用途モデルよりも優れた性能を発揮する可能性があるとされています。しかし、その設計やトレーニングプロセスは公開されていないため、医療現場では信頼性の検証が難しい状況です。今後は、こうしたAIツールの性能を客観的に評価する仕組みの構築が求められます。
まとめ
今回の研究は、医療分野で使われているAIツールの性能を再評価し、今後の臨床現場での導入に向けた重要な指針を示しました。今後は、AIツールの信頼性を確保するための独立した評価体制の構築が求められます。
原文の冒頭を表示(英語・3段落のみ)
Brief Communication
Open access
Published: 12 June 2026
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。