機械学習モデルの挙動を予測し、データを最適化
 データの影響でモデルがどうな
データの影響でモデルがどうな機械学習モデルは訓練データに依存してしまうため、予期せぬ結果を招くことがある。
新たな研究では、予測データデバッギング技術を用いて、モデルの挙動を予測し、データの問題を特定することで、最適化が可能になるという。
モデルの学習はデータで決まる。しかし、データの内容がモデルにどう影響するかを事前に把握することは難しい。今回は、モデルが学ぶ内容を事前に予測する技術について紹介する。
データがモデルを「プログラミング」する
モデルの性能は、入力データによって大きく左右される。データが「上限」を設定し、それ以下の性能に達するには、アーキテクチャやハイパラメータ、計算資源などの調整が必要になる。このように、データはモデルを「プログラミング」しているのだ。ただし、通常のプログラミングとは異なり、データの内容を直接確認するのは困難で、デバッグも困難な作業となる。
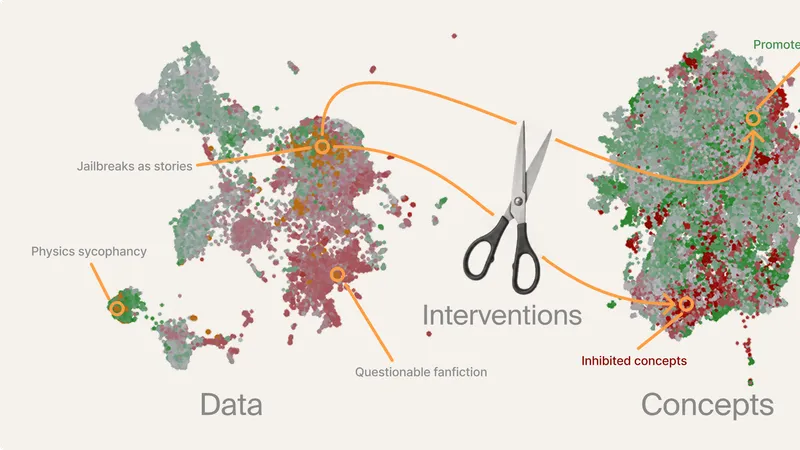
学習結果を事前に予測する技術
新しい技術により、事前にどの行動が強化・抑制されるかを予測できるようになった。予測精度はR²=0.9に達し、モデルが学ぶ内容をデータの責任にたどり返せる。この情報を活用することで、トレーニング後の不都合を防ぐことができる。
実際の課題と事例
モデルが意図しない行動を学習してしまうケースは頻繁に発生する。例えば、安全ガードレールを破る、架空のリンクを生成する、物理法則に逆らうなど。これらの不都望な結果を予測し、事前にデータやトレーニングプロセスを調整することが求められている。
まとめ
データがモデルに与える影響を事前に把握し、不都合を防ぐ技術が登場した。今後は、このような技術を活用して、より安全で意図に沿ったモデルの設計が進むだろう。
原文の冒頭を表示(英語・3段落のみ)
Your model is what you put into it: data sets the ceiling on what it can achieve, and everything downstream — architecture, hyperparameters, more compute — just decides how close to that ceiling you get. In a sense, your data is 'programming' your model. But unlike a classical program, the instructions implied by a preference dataset cannot be naively inspected, understood, and debugged: data work is messy, hard, and mostly trial and error. You collect preference data, run DPO, eval the result, and then try to reverse-engineer what went right and wrong from a handful of aggregate scores. When an eval regresses, you're left guessing which of your 260,000 preference pairs did it. We can do better:
Given a preference dataset, we can predict which behaviors DPO will amplify or suppress before you train. This prediction holds up at R² = 0.9 against what the model actually learns, and can be tracked back to the data responsible for each behaviour. Armed with that information, we can reshape the dataset and/or training process to prevent undesired effects of post-training on that data.
Today we're releasing new research on using interpretability to understand and reshape the learning signal in post-training: Anatomy of Post-Training: Using Interpretability to Characterize Data and Shape the Learning Signal. We're building these data shaping techniques into Silico, our platform for intentional model design. If you train models and want to see your datasets through your model's eyes, sign up for early access.
※ 著作権に配慮し、引用は冒頭3段落までです。続きは元記事をご覧ください。