เทคนิคการตรวจสอบข้อมูลก่อนฝึกโมเดล
 ปรับปรุงการเรี
ปรับปรุงการเรีการฝึกโมเดลเป็นกระบวนการที่ข้อมูลกำหนดขอบเขตของความสำเร็จ แต่การตรวจสอบข้อมูลก่อนฝึกช่วยให้คาดการณ์ผลลัพธ์ได้ดีขึ้น ทีมวิจัยนำเสนอวิธีการใหม่ที่ใช้ความเข้าใจในโมเดลเพื่อปรับปรุงข้อมูลและลดผลกระทบเชิงลบจากการฝึก
Show original excerpt (English · first 3 paragraphs)
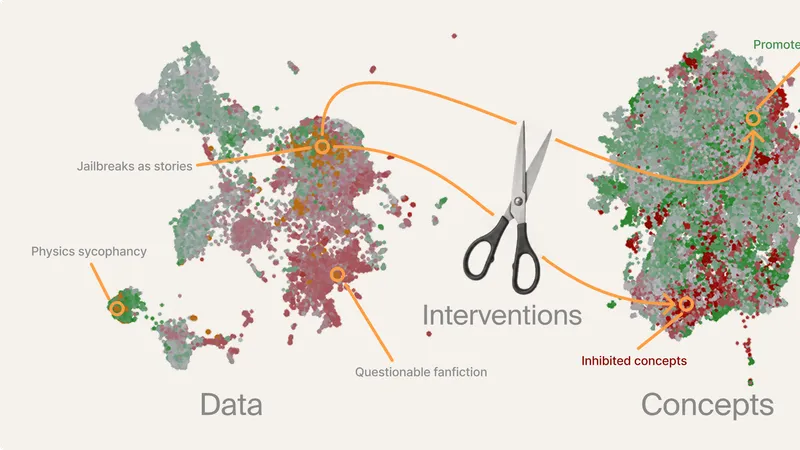
Your model is what you put into it: data sets the ceiling on what it can achieve, and everything downstream — architecture, hyperparameters, more compute — just decides how close to that ceiling you get. In a sense, your data is 'programming' your model. But unlike a classical program, the instructions implied by a preference dataset cannot be naively inspected, understood, and debugged: data work is messy, hard, and mostly trial and error. You collect preference data, run DPO, eval the result, and then try to reverse-engineer what went right and wrong from a handful of aggregate scores. When an eval regresses, you're left guessing which of your 260,000 preference pairs did it. We can do better:
Given a preference dataset, we can predict which behaviors DPO will amplify or suppress before you train. This prediction holds up at R² = 0.9 against what the model actually learns, and can be tracked back to the data responsible for each behaviour. Armed with that information, we can reshape the dataset and/or training process to prevent undesired effects of post-training on that data.
Today we're releasing new research on using interpretability to understand and reshape the learning signal in post-training: Anatomy of Post-Training: Using Interpretability to Characterize Data and Shape the Learning Signal. We're building these data shaping techniques into Silico, our platform for intentional model design. If you train models and want to see your datasets through your model's eyes, sign up for early access.
* For copyright reasons we quote only the first 3 paragraphs. Read the full article at the source.